Тем не менее, возможно иметь дело с отладкой, прежде чем продолжить:
- сделать запись и дамп памяти на блюдо,
- поэтапный подход к программированию,
- имеющий шаблон результата,
Дамп записи может быть реализован как минимальный макрос, поэтому он легко вставляется в любое место в программе QPU. Если необходимо проверить содержимое регистров, по которым выполняется инструкция, макрос можно ввести в соответствующую строку в исходном коде.
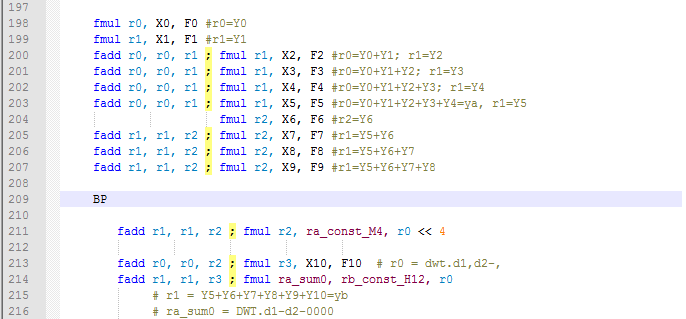
Рис. 6. Пример точки останова, вставленной в исходный код.
Когда вы смотрите на реализацию макроса вызова, он выглядит так, как показано ниже.
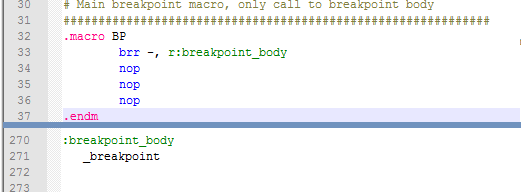
Рис. 7. Реализация макроса вызова точки останова.
Основной код использует два поддерживающих макроса для удаления набора регистров ( dump_regs ) и записи из памяти VPM в SDRAM ( store_dump ). Они также выполняют необходимое ожидание окончания передачи данных. Полный исходный код доступен для загрузки как часть примера проекта для QPU (см. Ниже) - файл qasm / breakpoint.qinc.

Рис. 8. Основной код макроса точки останова.
Макрокод ( _breakpoint ) сохраняет сброшенные регистры (набор регистров и батарей) в памяти VPM (Vertex Pipe Memory), а затем перезаписывает его в память, используемую совместно с ЦП. Адреса буфера передаются таблицами униформ и хранятся в двух регистрах из набора, скрытых под символическими именами: dbg_rfile_dump и dbg_accus_dump . После выполнения необходимых записей макроса программа QPU завершится, поэтому ожидающая программа ЦП будет выпущена и сможет записать содержимое буферов в читаемой форме. Пример такого логотипа представлен ниже:
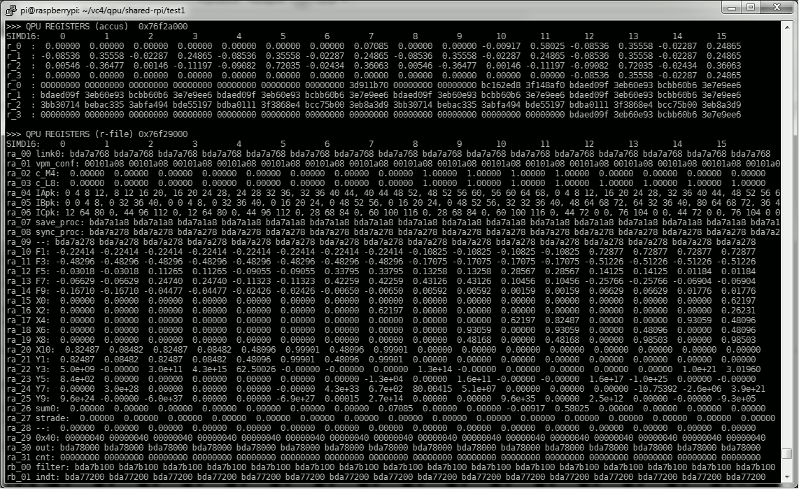
Рис. 9. Пример разряда регистра чипа QPU - простая техника отладки.
Примечание
Приведенный выше скриншот сделан для одного ядра QPU. Он состоит из двух частей: содержимого батарей и набора регистров (набор регистров rb виден только в части на этом рисунке). Каждый регистр указан горизонтально, а еще 16 элементов вектора SIMD слева направо. Батареи пишутся дважды, один раз как с плавающей точкой, а второй раз как 32-разрядные шестнадцатеричные числа. Специальные батареи r4 и r5 опущены. Для каждого регистра из набора в приложении определяется его формат и символическое имя.
В этом случае подход инкрементного программирования означает, что он начинается с программы для одного QPU, которая обрабатывает узел данных, а затем масштабирует программу до нескольких ядер и большого набора данных.
На первом этапе вы можете сосредоточиться на создании программы на ассемблере и проверке конкретного поведения QPU. Если это первая программа, созданная для QPU, то наверняка окажется, что некоторые инструкции работают не так, как ожидалось. «Будет обнаружено, что некоторые комбинации аргументов неприемлемы, поэтому инструкции не так гибки, как может показаться. В программировании QPU существуют некоторые взаимосвязи между последующими инструкциями, которые должны соблюдаться, в противном случае результат будет неточным (например, запись в регистр набора еще не доступна в следующей инструкции).
Это очевидно этап отладки, когда программа исправлена. Это не будет слишком хлопотно, если вы используете дамп записи. На этом этапе код также можно оптимизировать, в частности, с помощью двойственности АЛУ.
На следующем этапе вы можете добавить ptl, который обрабатывает следующие пакеты данных. Макрос для удаления регистров завершает программу, поэтому он не очень хорош для проверки поведения ptli. Тем не менее, это неудобство можно обойти. Вы можете скопировать цикл, так что это будет первая и вторая итерации в отдельных местах кода. Таким образом, можно будет проверить поведение ptli (то есть проверить, правильно ли изменены переменные от одной итерации к другой).
Следующий этап более сложный, вам нужно взять один QPU для многих. Вы можете начать с программы для двух QPU, и когда она заработает, она расширится на большее количество QPU. Следует помнить, что для многих QPU должна быть одна программа, может быть одна версия, но код должен быть один - размер кэша для оператора QPU ограничен!
Дайте каждому QPU различное количество данных. Новым элементом программы для многих ядер станет синхронизация между ядрами. Вы можете узнать, как это сделать, посмотрев готовые примеры.
На этом этапе результаты будут записаны в память VPM, а затем, когда все QPU будут завершены, вычисление будет сохранено в памяти, используемой совместно с CPU. Таким образом, они будут доступны для проверки.
Схема результатов расчета Даже при отладке программы для одного QPU это сложнее, чем для обычного процессора (такого как одноядерный ARM). Проблема заключается в большом наборе данных и его векторной природе. Чтобы справиться с этим, рекомендуется подготовить результат модели лица. Такой шаблон может быть рассчитан программой, написанной на C или C ++, и он должен предоставить шаблон для проверки: какие входные данные и правильные выходные данные для ключевых этапов лица. Удобно использовать текстовую форму, потому что результаты можно легко сравнить с результатами, полученными на QPU и перечисленными в журнале. Завершение можно сделать в какой электронной таблице (OpenOffice Calc и т. Д.), И тогда данные будут видны как векторные. Данные могут быть перенесены из консоли в журнал с помощью буфера обмена. Кроме того, вы можете включить проверку в приложение.
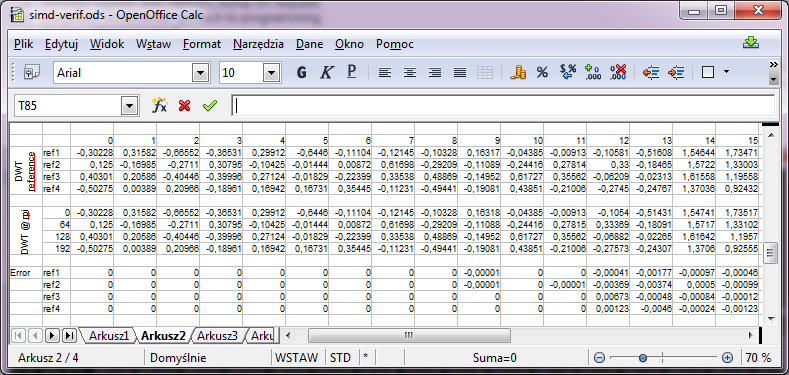
Рис. 10. Пример проверки SIMD16 в OpenOffice Calc.
Пример разработки программы с использованием QPU Вы можете скачать пример программы, которая ее использует, и рассматривать ее как основу для экспериментов с ядрами QPU. В этом примере вычисляется дискретное вейвлет-преобразование с использованием четырех ядер QPU и параллельное вычисление на основе SIMD16. Этот код содержит методы, описанные на этой странице, особенно полезные для других программистов, это может быть макрос для точки останова. Смотрите README.txt в этом пакете, чтобы прочитать подробности.
Это программное обеспечение было разработано на основе примера hello_fft путем внесения некоторых изменений и корректировок. Код QPU был написан с самого начала, но использует некоторые методы из примера вычисления FFT.
Пожалуйста, помните, что это программное обеспечение является просто демонстрацией методов программирования и доступно на условиях «КАК ЕСТЬ» без каких-либо гарантий. Лицензии на использование можно найти в исходных файлах.
Загрузите проект Eclipse, который содержит вычисления дискретного вейвлет-преобразования для ядер QPU (включая исходный код QPU).