- Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему...
- Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
- Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
- Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
- Кракозябри замість російських букв - як виправити
- Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
- ASCII - базова кодування тексту для латиниці
- Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
- Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
- Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
- Кракозябри замість російських букв - як виправити
- Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
- ASCII - базова кодування тексту для латиниці
- Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
- Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
- Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
- Кракозябри замість російських букв - як виправити
- Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
- ASCII - базова кодування тексту для латиниці
- Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
- Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
- Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
- Кракозябри замість російських букв - як виправити
Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Сьогодні ми поговоримо з вами про те, звідки беруться кракозябри на сайті і в програмах, які кодування тексту існують і які з них слід використовувати. Детально розглянемо історію їх розвитку, починаючи від базової ASCII, а також її розширених версій CP866, KOI8-R, Windows-1251 і закінчуючи сучасними кодуваннями консорціуму Юнікод UTF 16 і 8.
Кому-то ці відомості можуть здатися зайвими, але знали б ви, скільки мені приходить питань саме стосовно вилізли кракозябрами (не читав набору символів). Тепер у мене буде можливість відсилати всіх до тексту цієї статті і самостійно відшукувати свої косяки. Ну що ж, приготуйтеся вбирати інформацію і постарайтеся стежити за ходом розповіді.
ASCII - базова кодування тексту для латиниці
Розвиток кодувань текстів відбувалося одночасно з формуванням галузі IT, і вони за цей час встигли зазнати досить багато змін. Історично все починалося з досить-таки не милозвучно в російській вимові EBCDIC, яка дозволяла кодувати літери латинського алфавіту, арабські цифри і знаки пунктуації з керуючими символами.
Але все ж відправною точкою для розвитку сучасних кодувань текстів варто вважати знамениту ASCII (American Standard Code for Information Interchange, яка по-російському звичайно вимовляється як «аски»). Вона описує перші 128 символів з найбільш часто використовуваних англомовними користувачами - латинські букви, арабські цифри і розділові знаки.
Ще в ці 128 знаків, описаних в ASCII, потрапляли деякі службові символи навроде дужок, решіток, зірочок і т.п. Власне, ви самі можете побачити їх:
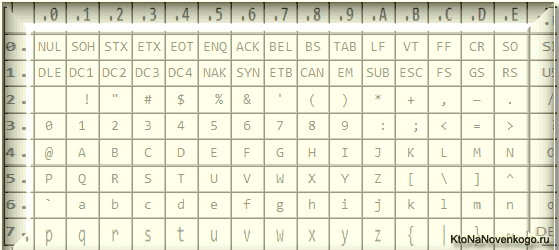
Саме ці 128 символів з початкового варіант ASCII стали стандартом, і в будь-який інший кодуванні ви їх обов'язково зустрінете і стояти вони будуть саме в такому порядку.
Але справа в тому, що за допомогою одного байта інформації можна закодувати НЕ 128, а цілих 256 різних значень (двійка в ступеня вісім дорівнює 256), тому слідом за базовою версією Аски з'явився цілий ряд розширених кодувань ASCII, в яких можна було крім 128 основних знаків закодувати ще й символи національної кодування (наприклад, російської).
Тут, напевно, варто ще трохи сказати про системи числення, які використовуються при описі. По-перше, як ви всі знаєте, комп'ютер працює тільки з числами в двійковій системі, а саме з нулями і одиницями ( «булева алгебра», якщо хто проходив в інституті або в школі). Один байт складається з восьми біт , Кожен з яких представляє з себе двійку в ступені, починаючи з нульової, і до двійки в сьомий:
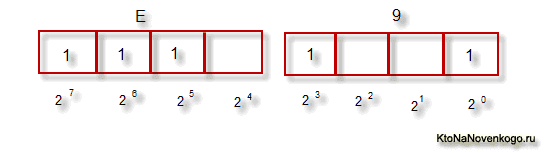
Не важко зрозуміти, що всіх можливих комбінацій нулів і одиниць в такій конструкції може бути тільки 256. Перекладати число з двійкової системи в десяткову досить просто. Потрібно просто скласти всі ступені двійки, над якими стоять одиниці.
У нашому прикладі це виходить 1 (2 певною мірою нуль) плюс 8 (два в ступені 3), плюс 32 (двійка в п'ятого ступеня), плюс 64 (в шостий), плюс 128 (в сьомий). Разом отримує 233 в десятковій системі числення. Як бачите, все дуже просто.
Але якщо ви придивитеся до таблиці з символами ASCII, то побачите, що вони представлені в шістнадцятковій кодуванні. Наприклад, «зірочка» відповідає в Аски шістнадцятиричним числу 2A. Напевно, вам відомо, що в шістнадцятковій системі числення використовуються крім арабських цифр ще й латинські літери від A (означає десять) до F (означає п'ятнадцять).
Ну так от, для перекладу двійкового числа в шістнадцяткове вдаються до наступного простому і наочному способу. Кожен байт інформації розбивають на дві частини по чотири біта, як показано на наведеному вище скріншоті. Т.ч. в кожній половинці байта двійковим кодом можна закодувати тільки шістнадцять значень (два в четвертого ступеня), що можна легко уявити шістнадцятковим числом.
Причому, в лівій половині байта вважати ступеня потрібно буде знову починаючи з нульової, а не так, як показано на скріншоті. В результаті, шляхом нехитрих обчислень, ми отримаємо, що на скріншоті закодовано число E9. Сподіваюся, що хід моїх міркувань і розгадка даного ребуса вам виявилися зрозумілі. Ну, а тепер продовжимо, власне, говорити про кодування тексту.
Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
Отже, ми з вами почали говорити про ASCII, яка була як би відправною точкою для розвитку всіх сучасних кодувань (Windows 1251, юнікод, UTF 8).
Спочатку в неї було закладено тільки 128 знаків латинського алфавіту, арабських цифр і ще чогось там, але в розширеній версії з'явилася можливість використовувати всі 256 значень, які можна закодувати в одному байті інформації. Тобто з'явилася можливість додати в Аски символи букв своєї мови.
Тут потрібно буде ще раз відволіктися, щоб пояснити - навіщо взагалі потрібні кодування текстів і чому це так важливо. Символи на екрані вашого комп'ютера формуються на основі двох речей - наборів векторних форм (уявлень) всіляких знаків (вони знаходяться в файлах з шрифтами, які встановлені на вашому комп'ютері ) І коду, який дозволяє висмикнути з цього набору векторних форм (файлу шрифту) саме той символ, який потрібно буде вставити в потрібне місце.
Зрозуміло, що за самі векторні форми відповідають шрифти, а ось за кодування відповідає операційна система і які використовуються в ній програми. Тобто будь-який текст на вашому комп'ютері буде являти собою набір байтів, в кожному з яких закодований один єдиний символ цього самого тексту.
Програма, яка відображає цей текст на екрані (текстовий редактор, браузер і т.п.), при розборі коду зчитує кодування чергового знака і шукає відповідну йому векторну форму в потрібному файлі шрифту, який підключений для відображення даного текстового документа. Все просто і банально.
Значить, щоб закодувати будь-який потрібний нам символ (наприклад, з національного алфавіту), має бути виконано дві умови - векторна форма цього знака повинна бути в використовуваному шрифті і цей символ можна було б закодувати в розширених кодуваннях ASCII в один байт. Тому таких варіантів існує ціла купа. Тільки лише для кодування символів російської мови існує кілька різновидів розширеної Аски.
Наприклад, спочатку з'явилася CP866, в якій була можливість використовувати символи російського алфавіту і вона була розширеною версією ASCII.
Тобто її верхня частина повністю збігалася з базовою версією Аски (128 символів латиниці, цифр і ще всякої лабуди), яка представлена на наведеному трохи вище скріншоті, а ось вже нижня частина таблиці з кодуванням CP866 мала вказаний на скріншоті трохи нижче вид і дозволяла закодувати ще 128 знаків (російські літери і всяка там псевдографіка):

Бачите, в правій колонці цифри починаються з 8, тому що числа з 0 до 7 відносяться до базової частини ASCII (див. перший скріншот). Т.ч. російська буква «М» в CP866 матиме код 9С (вона знаходиться на перетині відповідних рядка з 9 і стовпці з цифрою С в шістнадцятковій системі числення), який можна записати в одному байті інформації, і при наявності відповідного шрифту з російськими символами ця буква без проблем відобразиться в тексті.
Звідки взялося таке кількість псевдографіки в CP866? Тут вся справа в тому, що це кодування для російського тексту розроблялася ще в ті волохаті року, коли не було такого поширення графічних операційних систем як зараз. А в Досі, і подібних їй текстових операционках, псевдографіка дозволяла хоч якось урізноманітнити оформлення текстів і тому нею рясніє CP866 і всі інші її ровесниці з розряду розширених версій Аски.
CP866 поширювала компанія IBM, але крім цього для символів російської мови були розроблені ще ряд кодувань, наприклад, до цього ж типу (розширених ASCII) можна віднести KOI8-R:

Принцип її роботи залишився той же самий, що і у описаної раніше CP866 - кожен символ тексту кодується одним єдиним байтом. На скріншоті показана друга половина таблиці KOI8-R, тому що перша половина повністю відповідає базовій Аски, яка показана на першому скріншоті в цій статті.
Серед особливостей кодування KOI8-R можна відзначити те, що російські букви в її таблиці йдуть не в алфавітному порядку, як це, наприклад, зробили в CP866.
Якщо подивитеся на найперший скріншот (базової частини, яка входить в усі розширені кодування), то помітите, що в KOI8-R російські літери розташовані в тих же елементах таблиці, що і співзвучні їм літери латинського алфавіту з першої частини таблиці. Це було зроблено для зручності переходу з російських символів на латинські шляхом відкидання всього одного біта (два в сьомий ступеня або 128).
Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
Подальший розвиток кодувань тексту було пов'язано з тим, що набирали популярність графічні операційні системи і необхідність використання псевдографіки в них з часом зникла. В результаті виникла ціла група, яка за своєю суттю і раніше були розширеними версіями Аски (один символ тексту кодується всього одним байтом інформації), але вже без використання символів псевдографіки.
Вони ставилися до так званим ANSI кодувань, які були розроблені американським інститутом стандартизації. У просторіччі ще використовувалося назву кирилиця для варіанту з підтримкою російської мови. Прикладом такої може служити Windows 1251.
Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли відсутні символи російської типографіки (окрім знака наголоси), а також символи, які використовуються в близьких до російського слов'янських мовах (українській, білоруській і т.д. ):
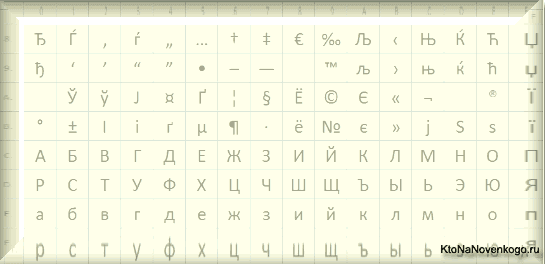
Через такої великої кількості кодувань російської мови, у виробників шрифтів і виробників програмного забезпечення постійно виникала головний біль, а у нас з вам, шановні читачі, часто вилазили ті самі горезвісні кракозябри, коли відбувалася плутанина з використовуваної в тексті версією.
Дуже часто вони вилазили при відправці і отриманні повідомлень по електронній пошті, що спричинило за собою створення дуже складних перекодіровочний таблиць, які, власне, вирішити цю проблему в корені не змогли, і часто користувачі для листування використовували транслит латинських букв , Щоб уникнути горезвісних кракозябрами при використанні російських кодувань подібних CP866, KOI8-R або Windows 1251.
По суті, кракозябри, вилазящіе замість російського тексту, були результатом некоректного використання кодування даного мови, яка не відповідала тій, в якій було закодовано текстове повідомлення спочатку.
Припустимо, якщо символи, закодовані за допомогою CP866, спробувати відобразити, використовуючи кодову таблицю Windows 1251, то ці самі кракозябри (безглуздий набір знаків) і вилізуть, повністю замінивши собою текст повідомлення.
Аналогічна ситуація дуже часто виникає при створення сайтів на WordPress і Joomla , Форумів або блогів, коли текст з російськими символами помилково зберігається не в тій кодуванні, яка використовується на сайті за замовчуванням, або ж не в тому текстовому редакторі, який додає в код відсебеньки невидиму неозброєним оком.
Зрештою така ситуація з безліччю кодувань і постійно вилазять кракозябрами багатьом набридла, з'явилися передумови до створення нової універсальної варіації, яка б замінила собою всі існуючі і вирішила б, нарешті, на корені проблему з появою не читав текстів. Крім цього існувала проблема мов подібних китайському, де символів мови було набагато більше, ніж 256.
Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
Ці тисячі знаків мовної групи південно-східній Азії ніяк неможливо було описати в одному байті інформації, який виділявся для кодування символів в розширених версіях ASCII. В результаті був створений консорціум під назвою Юнікод (Unicode - Unicode Consortium ) При співпраці багатьох лідерів IT індустрії (ті, хто виробляє софт, хто кодує залізо, хто створює шрифти), які були зацікавлені в появі універсального кодування тексту.
Першою варіацією, що вийшла під егідою консорціуму Юнікод, була UTF 32. Цифра в назві кодування означає кількість біт, яке використовується для кодування одного символу. 32 біта становлять 4 байта інформації, які знадобляться для кодування одного єдиного знака в новій універсальній кодуванні UTF.
В результаті чого, один і той же файл з текстом, закодований в розширеній версії ASCII і в UTF-32, в останньому випадку буде мати розмір (важити) в чотири рази більше. Це погано, але зате тепер у нас з'явилася можливість закодувати за допомогою ЮТФ число знаків, що дорівнює двом в тридцять другого ступеня (мільярди символів, які покриють будь реально необхідне значення з колосальним запасом).
Але багатьом країнам з мовами європейської групи таку величезну кількість знаків використовувати в кодуванні зовсім і не було необхідності, однак при залученні UTF-32 вони ні за що ні про що отримували чотириразове збільшення ваги текстових документів, а в результаті і збільшення обсягу інтернет трафіку і обсягу збережених даних. Це багато, і таке марнотратство собі ніхто не міг дозволити.
В результаті розвитку Юникода з'явилася UTF-16, яка вийшла настільки вдалою, що була прийнята за замовчуванням як базове простір для всіх символів, які у нас використовуються. Вона використовує два байта для кодування одного знака. Давайте подивимося, як ця справа виглядає.
В операційній системі Windows ви можете пройти по шляху «Пуск» - «Програми» - «Стандартні» - «Службові» - «Таблиця символів». В результаті відкриється таблиця з векторними формами всіх встановлених у вас в системі шрифтів. Якщо ви виберете в «Додаткових параметрах» набір знаків Юнікод, то зможете побачити для кожного шрифту окремо весь асортимент входять до нього символів.
До речі, клацнувши по будь-якому з них, ви зможете побачити його багатобайтових код у форматі UTF-16, що складається з чотирьох шістнадцятирічних цифр:
Скільки символів можна закодувати в UTF-16 за допомогою 16 біт? 65 536 (два в ступені шістнадцять), і саме це число було прийнято за базову простір в Юникоде. Крім цього існують способи закодувати за допомогою неї і близько двох мільйонів знаків, але обмежилися розширеним простором в мільйон символів тексту.
Але навіть ця вдала версія кодування Юнікоду не принесла особливого задоволення тим, хто писав, припустимо, програми тільки на англійській мові, бо у них, після переходу від розширеної версії ASCII до UTF-16, вага документів збільшувався в два рази (один байт на один символ в Аски і два байта на той же самий символ в ЮТФ-16).
Ось саме для задоволення всіх і вся в консорціумі Unicode було вирішено придумати кодування змінної довжини. Її назвали UTF-8. Незважаючи на вісімку в назві, вона дійсно має змінну довжину, тобто кожен символ тексту може бути закодований в послідовність довжиною від одного до шести байт.
На практиці ж в UTF-8 використовується тільки діапазон від одного до чотирьох байт, тому що за чотирма байтами коду нічого вже навіть теоретично не можливо уявити. Всі латинські знаки в ній кодуються в один байт, так само як і в старій добрій ASCII.
Що примітно, в разі кодування тільки латиниці, навіть ті програми, які не розуміють Юнікод, все одно прочитають те, що закодовано в ЮТФ-8. Тобто базова частина Аски просто перейшла в це дітище консорціуму Unicode.
Кириличні ж знаки в UTF-8 кодуються в два байта, а, наприклад, грузинські - в три байта. Консорціум Юнікод після створення UTF 16 і 8 вирішив основну проблему - тепер у нас в шрифтах існує єдине кодове простір. І тепер їх виробникам залишається тільки виходячи зі своїх сил і можливостей заповнювати його векторними формами символів тексту. Зараз в набори навіть емодзі смайли додають .
У наведеній трохи вище «Таблиці символів» видно, що різні шрифти підтримують різну кількість знаків. Деякі насичені символами Юнікоду шрифти можуть важити дуже пристойно. Але зате тепер вони відрізняються не тим, що вони створені для різних кодувань, а тим, що виробник шрифту заповнив або не заповнить єдине кодове простір тими чи іншими векторними формами до кінця.
Кракозябри замість російських букв - як виправити
Давайте тепер подивимося, як з'являються замість тексту кракозябри або, іншими словами, як вибирається правильна кодування для російського тексту. Власне, вона задається в тій програмі, в якій ви створюєте або редагуєте цей самий текст, або ж код з використанням текстових фрагментів.
Для редагування та створення текстових файлів особисто я використовую дуже хороший, на мій погляд, Html і PHP редактор Notepad ++ . Втім, він може підсвічувати синтаксис ще доброї сотні мов програмування і розмітки, а також має можливість розширення за допомогою плагінів. Читайте детальний огляд цієї чудової програми за посиланням.
Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Сьогодні ми поговоримо з вами про те, звідки беруться кракозябри на сайті і в програмах, які кодування тексту існують і які з них слід використовувати. Детально розглянемо історію їх розвитку, починаючи від базової ASCII, а також її розширених версій CP866, KOI8-R, Windows-1251 і закінчуючи сучасними кодуваннями консорціуму Юнікод UTF 16 і 8.
Кому-то ці відомості можуть здатися зайвими, але знали б ви, скільки мені приходить питань саме стосовно вилізли кракозябрами (не читав набору символів). Тепер у мене буде можливість відсилати всіх до тексту цієї статті і самостійно відшукувати свої косяки. Ну що ж, приготуйтеся вбирати інформацію і постарайтеся стежити за ходом розповіді.
ASCII - базова кодування тексту для латиниці
Розвиток кодувань текстів відбувалося одночасно з формуванням галузі IT, і вони за цей час встигли зазнати досить багато змін. Історично все починалося з досить-таки не милозвучно в російській вимові EBCDIC, яка дозволяла кодувати літери латинського алфавіту, арабські цифри і знаки пунктуації з керуючими символами.
Але все ж відправною точкою для розвитку сучасних кодувань текстів варто вважати знамениту ASCII (American Standard Code for Information Interchange, яка по-російському звичайно вимовляється як «аски»). Вона описує перші 128 символів з найбільш часто використовуваних англомовними користувачами - латинські букви, арабські цифри і розділові знаки.
Ще в ці 128 знаків, описаних в ASCII, потрапляли деякі службові символи навроде дужок, решіток, зірочок і т.п. Власне, ви самі можете побачити їх:
Саме ці 128 символів з початкового варіант ASCII стали стандартом, і в будь-який інший кодуванні ви їх обов'язково зустрінете і стояти вони будуть саме в такому порядку.
Але справа в тому, що за допомогою одного байта інформації можна закодувати НЕ 128, а цілих 256 різних значень (двійка в ступеня вісім дорівнює 256), тому слідом за базовою версією Аски з'явився цілий ряд розширених кодувань ASCII, в яких можна було крім 128 основних знаків закодувати ще й символи національної кодування (наприклад, російської).
Тут, напевно, варто ще трохи сказати про системи числення, які використовуються при описі. По-перше, як ви всі знаєте, комп'ютер працює тільки з числами в двійковій системі, а саме з нулями і одиницями ( «булева алгебра», якщо хто проходив в інституті або в школі). Один байт складається з восьми біт , Кожен з яких представляє з себе двійку в ступені, починаючи з нульової, і до двійки в сьомий:
Не важко зрозуміти, що всіх можливих комбінацій нулів і одиниць в такій конструкції може бути тільки 256. Перекладати число з двійкової системи в десяткову досить просто. Потрібно просто скласти всі ступені двійки, над якими стоять одиниці.
У нашому прикладі це виходить 1 (2 певною мірою нуль) плюс 8 (два в ступені 3), плюс 32 (двійка в п'ятого ступеня), плюс 64 (в шостий), плюс 128 (в сьомий). Разом отримує 233 в десятковій системі числення. Як бачите, все дуже просто.
Але якщо ви придивитеся до таблиці з символами ASCII, то побачите, що вони представлені в шістнадцятковій кодуванні. Наприклад, «зірочка» відповідає в Аски шістнадцятиричним числу 2A. Напевно, вам відомо, що в шістнадцятковій системі числення використовуються крім арабських цифр ще й латинські літери від A (означає десять) до F (означає п'ятнадцять).
Ну так от, для перекладу двійкового числа в шістнадцяткове вдаються до наступного простому і наочному способу. Кожен байт інформації розбивають на дві частини по чотири біта, як показано на наведеному вище скріншоті. Т.ч. в кожній половинці байта двійковим кодом можна закодувати тільки шістнадцять значень (два в четвертого ступеня), що можна легко уявити шістнадцятковим числом.
Причому, в лівій половині байта вважати ступеня потрібно буде знову починаючи з нульової, а не так, як показано на скріншоті. В результаті, шляхом нехитрих обчислень, ми отримаємо, що на скріншоті закодовано число E9. Сподіваюся, що хід моїх міркувань і розгадка даного ребуса вам виявилися зрозумілі. Ну, а тепер продовжимо, власне, говорити про кодування тексту.
Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
Отже, ми з вами почали говорити про ASCII, яка була як би відправною точкою для розвитку всіх сучасних кодувань (Windows 1251, юнікод, UTF 8).
Спочатку в неї було закладено тільки 128 знаків латинського алфавіту, арабських цифр і ще чогось там, але в розширеній версії з'явилася можливість використовувати всі 256 значень, які можна закодувати в одному байті інформації. Тобто з'явилася можливість додати в Аски символи букв своєї мови.
Тут потрібно буде ще раз відволіктися, щоб пояснити - навіщо взагалі потрібні кодування текстів і чому це так важливо. Символи на екрані вашого комп'ютера формуються на основі двох речей - наборів векторних форм (уявлень) всіляких знаків (вони знаходяться в файлах з шрифтами, які встановлені на вашому комп'ютері ) І коду, який дозволяє висмикнути з цього набору векторних форм (файлу шрифту) саме той символ, який потрібно буде вставити в потрібне місце.
Зрозуміло, що за самі векторні форми відповідають шрифти, а ось за кодування відповідає операційна система і які використовуються в ній програми. Тобто будь-який текст на вашому комп'ютері буде являти собою набір байтів, в кожному з яких закодований один єдиний символ цього самого тексту.
Програма, яка відображає цей текст на екрані (текстовий редактор, браузер і т.п.), при розборі коду зчитує кодування чергового знака і шукає відповідну йому векторну форму в потрібному файлі шрифту, який підключений для відображення даного текстового документа. Все просто і банально.
Значить, щоб закодувати будь-який потрібний нам символ (наприклад, з національного алфавіту), має бути виконано дві умови - векторна форма цього знака повинна бути в використовуваному шрифті і цей символ можна було б закодувати в розширених кодуваннях ASCII в один байт. Тому таких варіантів існує ціла купа. Тільки лише для кодування символів російської мови існує кілька різновидів розширеної Аски.
Наприклад, спочатку з'явилася CP866, в якій була можливість використовувати символи російського алфавіту і вона була розширеною версією ASCII.
Тобто її верхня частина повністю збігалася з базовою версією Аски (128 символів латиниці, цифр і ще всякої лабуди), яка представлена на наведеному трохи вище скріншоті, а ось вже нижня частина таблиці з кодуванням CP866 мала вказаний на скріншоті трохи нижче вид і дозволяла закодувати ще 128 знаків (російські літери і всяка там псевдографіка):
Бачите, в правій колонці цифри починаються з 8, тому що числа з 0 до 7 відносяться до базової частини ASCII (див. перший скріншот). Т.ч. російська буква «М» в CP866 матиме код 9С (вона знаходиться на перетині відповідних рядка з 9 і стовпці з цифрою С в шістнадцятковій системі числення), який можна записати в одному байті інформації, і при наявності відповідного шрифту з російськими символами ця буква без проблем відобразиться в тексті.
Звідки взялося таке кількість псевдографіки в CP866? Тут вся справа в тому, що це кодування для російського тексту розроблялася ще в ті волохаті року, коли не було такого поширення графічних операційних систем як зараз. А в Досі, і подібних їй текстових операционках, псевдографіка дозволяла хоч якось урізноманітнити оформлення текстів і тому нею рясніє CP866 і всі інші її ровесниці з розряду розширених версій Аски.
CP866 поширювала компанія IBM, але крім цього для символів російської мови були розроблені ще ряд кодувань, наприклад, до цього ж типу (розширених ASCII) можна віднести KOI8-R:
Принцип її роботи залишився той же самий, що і у описаної раніше CP866 - кожен символ тексту кодується одним єдиним байтом. На скріншоті показана друга половина таблиці KOI8-R, тому що перша половина повністю відповідає базовій Аски, яка показана на першому скріншоті в цій статті.
Серед особливостей кодування KOI8-R можна відзначити те, що російські букви в її таблиці йдуть не в алфавітному порядку, як це, наприклад, зробили в CP866.
Якщо подивитеся на найперший скріншот (базової частини, яка входить в усі розширені кодування), то помітите, що в KOI8-R російські літери розташовані в тих же елементах таблиці, що і співзвучні їм літери латинського алфавіту з першої частини таблиці. Це було зроблено для зручності переходу з російських символів на латинські шляхом відкидання всього одного біта (два в сьомий ступеня або 128).
Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
Подальший розвиток кодувань тексту було пов'язано з тим, що набирали популярність графічні операційні системи і необхідність використання псевдографіки в них з часом зникла. В результаті виникла ціла група, яка за своєю суттю і раніше були розширеними версіями Аски (один символ тексту кодується всього одним байтом інформації), але вже без використання символів псевдографіки.
Вони ставилися до так званим ANSI кодувань, які були розроблені американським інститутом стандартизації. У просторіччі ще використовувалося назву кирилиця для варіанту з підтримкою російської мови. Прикладом такої може служити Windows 1251.
Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли відсутні символи російської типографіки (окрім знака наголоси), а також символи, які використовуються в близьких до російського слов'янських мовах (українській, білоруській і т.д. ):
Через такої великої кількості кодувань російської мови, у виробників шрифтів і виробників програмного забезпечення постійно виникала головний біль, а у нас з вам, шановні читачі, часто вилазили ті самі горезвісні кракозябри, коли відбувалася плутанина з використовуваної в тексті версією.
Дуже часто вони вилазили при відправці і отриманні повідомлень по електронній пошті, що спричинило за собою створення дуже складних перекодіровочний таблиць, які, власне, вирішити цю проблему в корені не змогли, і часто користувачі для листування використовували транслит латинських букв , Щоб уникнути горезвісних кракозябрами при використанні російських кодувань подібних CP866, KOI8-R або Windows 1251.
По суті, кракозябри, вилазящіе замість російського тексту, були результатом некоректного використання кодування даного мови, яка не відповідала тій, в якій було закодовано текстове повідомлення спочатку.
Припустимо, якщо символи, закодовані за допомогою CP866, спробувати відобразити, використовуючи кодову таблицю Windows 1251, то ці самі кракозябри (безглуздий набір знаків) і вилізуть, повністю замінивши собою текст повідомлення.
Аналогічна ситуація дуже часто виникає при створення сайтів на WordPress і Joomla , Форумів або блогів, коли текст з російськими символами помилково зберігається не в тій кодуванні, яка використовується на сайті за замовчуванням, або ж не в тому текстовому редакторі, який додає в код відсебеньки невидиму неозброєним оком.
Зрештою така ситуація з безліччю кодувань і постійно вилазять кракозябрами багатьом набридла, з'явилися передумови до створення нової універсальної варіації, яка б замінила собою всі існуючі і вирішила б, нарешті, на корені проблему з появою не читав текстів. Крім цього існувала проблема мов подібних китайському, де символів мови було набагато більше, ніж 256.
Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
Ці тисячі знаків мовної групи південно-східній Азії ніяк неможливо було описати в одному байті інформації, який виділявся для кодування символів в розширених версіях ASCII. В результаті був створений консорціум під назвою Юнікод (Unicode - Unicode Consortium ) При співпраці багатьох лідерів IT індустрії (ті, хто виробляє софт, хто кодує залізо, хто створює шрифти), які були зацікавлені в появі універсального кодування тексту.
Першою варіацією, що вийшла під егідою консорціуму Юнікод, була UTF 32. Цифра в назві кодування означає кількість біт, яке використовується для кодування одного символу. 32 біта становлять 4 байта інформації, які знадобляться для кодування одного єдиного знака в новій універсальній кодуванні UTF.
В результаті чого, один і той же файл з текстом, закодований в розширеній версії ASCII і в UTF-32, в останньому випадку буде мати розмір (важити) в чотири рази більше. Це погано, але зате тепер у нас з'явилася можливість закодувати за допомогою ЮТФ число знаків, що дорівнює двом в тридцять другого ступеня (мільярди символів, які покриють будь реально необхідне значення з колосальним запасом).
Але багатьом країнам з мовами європейської групи таку величезну кількість знаків використовувати в кодуванні зовсім і не було необхідності, однак при залученні UTF-32 вони ні за що ні про що отримували чотириразове збільшення ваги текстових документів, а в результаті і збільшення обсягу інтернет трафіку і обсягу збережених даних. Це багато, і таке марнотратство собі ніхто не міг дозволити.
В результаті розвитку Юникода з'явилася UTF-16, яка вийшла настільки вдалою, що була прийнята за замовчуванням як базове простір для всіх символів, які у нас використовуються. Вона використовує два байта для кодування одного знака. Давайте подивимося, як ця справа виглядає.
В операційній системі Windows ви можете пройти по шляху «Пуск» - «Програми» - «Стандартні» - «Службові» - «Таблиця символів». В результаті відкриється таблиця з векторними формами всіх встановлених у вас в системі шрифтів. Якщо ви виберете в «Додаткових параметрах» набір знаків Юнікод, то зможете побачити для кожного шрифту окремо весь асортимент входять до нього символів.
До речі, клацнувши по будь-якому з них, ви зможете побачити його багатобайтових код у форматі UTF-16, що складається з чотирьох шістнадцятирічних цифр:
Скільки символів можна закодувати в UTF-16 за допомогою 16 біт? 65 536 (два в ступені шістнадцять), і саме це число було прийнято за базову простір в Юникоде. Крім цього існують способи закодувати за допомогою неї і близько двох мільйонів знаків, але обмежилися розширеним простором в мільйон символів тексту.
Але навіть ця вдала версія кодування Юнікоду не принесла особливого задоволення тим, хто писав, припустимо, програми тільки на англійській мові, бо у них, після переходу від розширеної версії ASCII до UTF-16, вага документів збільшувався в два рази (один байт на один символ в Аски і два байта на той же самий символ в ЮТФ-16).
Ось саме для задоволення всіх і вся в консорціумі Unicode було вирішено придумати кодування змінної довжини. Її назвали UTF-8. Незважаючи на вісімку в назві, вона дійсно має змінну довжину, тобто кожен символ тексту може бути закодований в послідовність довжиною від одного до шести байт.
На практиці ж в UTF-8 використовується тільки діапазон від одного до чотирьох байт, тому що за чотирма байтами коду нічого вже навіть теоретично не можливо уявити. Всі латинські знаки в ній кодуються в один байт, так само як і в старій добрій ASCII.
Що примітно, в разі кодування тільки латиниці, навіть ті програми, які не розуміють Юнікод, все одно прочитають те, що закодовано в ЮТФ-8. Тобто базова частина Аски просто перейшла в це дітище консорціуму Unicode.
Кириличні ж знаки в UTF-8 кодуються в два байта, а, наприклад, грузинські - в три байта. Консорціум Юнікод після створення UTF 16 і 8 вирішив основну проблему - тепер у нас в шрифтах існує єдине кодове простір. І тепер їх виробникам залишається тільки виходячи зі своїх сил і можливостей заповнювати його векторними формами символів тексту. Зараз в набори навіть емодзі смайли додають .
У наведеній трохи вище «Таблиці символів» видно, що різні шрифти підтримують різну кількість знаків. Деякі насичені символами Юнікоду шрифти можуть важити дуже пристойно. Але зате тепер вони відрізняються не тим, що вони створені для різних кодувань, а тим, що виробник шрифту заповнив або не заповнить єдине кодове простір тими чи іншими векторними формами до кінця.
Кракозябри замість російських букв - як виправити
Давайте тепер подивимося, як з'являються замість тексту кракозябри або, іншими словами, як вибирається правильна кодування для російського тексту. Власне, вона задається в тій програмі, в якій ви створюєте або редагуєте цей самий текст, або ж код з використанням текстових фрагментів.
Для редагування та створення текстових файлів особисто я використовую дуже хороший, на мій погляд, Html і PHP редактор Notepad ++ . Втім, він може підсвічувати синтаксис ще доброї сотні мов програмування і розмітки, а також має можливість розширення за допомогою плагінів. Читайте детальний огляд цієї чудової програми за посиланням.
Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Сьогодні ми поговоримо з вами про те, звідки беруться кракозябри на сайті і в програмах, які кодування тексту існують і які з них слід використовувати. Детально розглянемо історію їх розвитку, починаючи від базової ASCII, а також її розширених версій CP866, KOI8-R, Windows-1251 і закінчуючи сучасними кодуваннями консорціуму Юнікод UTF 16 і 8.
Кому-то ці відомості можуть здатися зайвими, але знали б ви, скільки мені приходить питань саме стосовно вилізли кракозябрами (не читав набору символів). Тепер у мене буде можливість відсилати всіх до тексту цієї статті і самостійно відшукувати свої косяки. Ну що ж, приготуйтеся вбирати інформацію і постарайтеся стежити за ходом розповіді.
ASCII - базова кодування тексту для латиниці
Розвиток кодувань текстів відбувалося одночасно з формуванням галузі IT, і вони за цей час встигли зазнати досить багато змін. Історично все починалося з досить-таки не милозвучно в російській вимові EBCDIC, яка дозволяла кодувати літери латинського алфавіту, арабські цифри і знаки пунктуації з керуючими символами.
Але все ж відправною точкою для розвитку сучасних кодувань текстів варто вважати знамениту ASCII (American Standard Code for Information Interchange, яка по-російському звичайно вимовляється як «аски»). Вона описує перші 128 символів з найбільш часто використовуваних англомовними користувачами - латинські букви, арабські цифри і розділові знаки.
Ще в ці 128 знаків, описаних в ASCII, потрапляли деякі службові символи навроде дужок, решіток, зірочок і т.п. Власне, ви самі можете побачити їх:
Саме ці 128 символів з початкового варіант ASCII стали стандартом, і в будь-який інший кодуванні ви їх обов'язково зустрінете і стояти вони будуть саме в такому порядку.
Але справа в тому, що за допомогою одного байта інформації можна закодувати НЕ 128, а цілих 256 різних значень (двійка в ступеня вісім дорівнює 256), тому слідом за базовою версією Аски з'явився цілий ряд розширених кодувань ASCII, в яких можна було крім 128 основних знаків закодувати ще й символи національної кодування (наприклад, російської).
Тут, напевно, варто ще трохи сказати про системи числення, які використовуються при описі. По-перше, як ви всі знаєте, комп'ютер працює тільки з числами в двійковій системі, а саме з нулями і одиницями ( «булева алгебра», якщо хто проходив в інституті або в школі). Один байт складається з восьми біт , Кожен з яких представляє з себе двійку в ступені, починаючи з нульової, і до двійки в сьомий:
Не важко зрозуміти, що всіх можливих комбінацій нулів і одиниць в такій конструкції може бути тільки 256. Перекладати число з двійкової системи в десяткову досить просто. Потрібно просто скласти всі ступені двійки, над якими стоять одиниці.
У нашому прикладі це виходить 1 (2 певною мірою нуль) плюс 8 (два в ступені 3), плюс 32 (двійка в п'ятого ступеня), плюс 64 (в шостий), плюс 128 (в сьомий). Разом отримує 233 в десятковій системі числення. Як бачите, все дуже просто.
Але якщо ви придивитеся до таблиці з символами ASCII, то побачите, що вони представлені в шістнадцятковій кодуванні. Наприклад, «зірочка» відповідає в Аски шістнадцятиричним числу 2A. Напевно, вам відомо, що в шістнадцятковій системі числення використовуються крім арабських цифр ще й латинські літери від A (означає десять) до F (означає п'ятнадцять).
Ну так от, для перекладу двійкового числа в шістнадцяткове вдаються до наступного простому і наочному способу. Кожен байт інформації розбивають на дві частини по чотири біта, як показано на наведеному вище скріншоті. Т.ч. в кожній половинці байта двійковим кодом можна закодувати тільки шістнадцять значень (два в четвертого ступеня), що можна легко уявити шістнадцятковим числом.
Причому, в лівій половині байта вважати ступеня потрібно буде знову починаючи з нульової, а не так, як показано на скріншоті. В результаті, шляхом нехитрих обчислень, ми отримаємо, що на скріншоті закодовано число E9. Сподіваюся, що хід моїх міркувань і розгадка даного ребуса вам виявилися зрозумілі. Ну, а тепер продовжимо, власне, говорити про кодування тексту.
Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
Отже, ми з вами почали говорити про ASCII, яка була як би відправною точкою для розвитку всіх сучасних кодувань (Windows 1251, юнікод, UTF 8).
Спочатку в неї було закладено тільки 128 знаків латинського алфавіту, арабських цифр і ще чогось там, але в розширеній версії з'явилася можливість використовувати всі 256 значень, які можна закодувати в одному байті інформації. Тобто з'явилася можливість додати в Аски символи букв своєї мови.
Тут потрібно буде ще раз відволіктися, щоб пояснити - навіщо взагалі потрібні кодування текстів і чому це так важливо. Символи на екрані вашого комп'ютера формуються на основі двох речей - наборів векторних форм (уявлень) всіляких знаків (вони знаходяться в файлах з шрифтами, які встановлені на вашому комп'ютері ) І коду, який дозволяє висмикнути з цього набору векторних форм (файлу шрифту) саме той символ, який потрібно буде вставити в потрібне місце.
Зрозуміло, що за самі векторні форми відповідають шрифти, а ось за кодування відповідає операційна система і які використовуються в ній програми. Тобто будь-який текст на вашому комп'ютері буде являти собою набір байтів, в кожному з яких закодований один єдиний символ цього самого тексту.
Програма, яка відображає цей текст на екрані (текстовий редактор, браузер і т.п.), при розборі коду зчитує кодування чергового знака і шукає відповідну йому векторну форму в потрібному файлі шрифту, який підключений для відображення даного текстового документа. Все просто і банально.
Значить, щоб закодувати будь-який потрібний нам символ (наприклад, з національного алфавіту), має бути виконано дві умови - векторна форма цього знака повинна бути в використовуваному шрифті і цей символ можна було б закодувати в розширених кодуваннях ASCII в один байт. Тому таких варіантів існує ціла купа. Тільки лише для кодування символів російської мови існує кілька різновидів розширеної Аски.
Наприклад, спочатку з'явилася CP866, в якій була можливість використовувати символи російського алфавіту і вона була розширеною версією ASCII.
Тобто її верхня частина повністю збігалася з базовою версією Аски (128 символів латиниці, цифр і ще всякої лабуди), яка представлена на наведеному трохи вище скріншоті, а ось вже нижня частина таблиці з кодуванням CP866 мала вказаний на скріншоті трохи нижче вид і дозволяла закодувати ще 128 знаків (російські літери і всяка там псевдографіка):
Бачите, в правій колонці цифри починаються з 8, тому що числа з 0 до 7 відносяться до базової частини ASCII (див. перший скріншот). Т.ч. російська буква «М» в CP866 матиме код 9С (вона знаходиться на перетині відповідних рядка з 9 і стовпці з цифрою С в шістнадцятковій системі числення), який можна записати в одному байті інформації, і при наявності відповідного шрифту з російськими символами ця буква без проблем відобразиться в тексті.
Звідки взялося таке кількість псевдографіки в CP866? Тут вся справа в тому, що це кодування для російського тексту розроблялася ще в ті волохаті року, коли не було такого поширення графічних операційних систем як зараз. А в Досі, і подібних їй текстових операционках, псевдографіка дозволяла хоч якось урізноманітнити оформлення текстів і тому нею рясніє CP866 і всі інші її ровесниці з розряду розширених версій Аски.
CP866 поширювала компанія IBM, але крім цього для символів російської мови були розроблені ще ряд кодувань, наприклад, до цього ж типу (розширених ASCII) можна віднести KOI8-R:
Принцип її роботи залишився той же самий, що і у описаної раніше CP866 - кожен символ тексту кодується одним єдиним байтом. На скріншоті показана друга половина таблиці KOI8-R, тому що перша половина повністю відповідає базовій Аски, яка показана на першому скріншоті в цій статті.
Серед особливостей кодування KOI8-R можна відзначити те, що російські букви в її таблиці йдуть не в алфавітному порядку, як це, наприклад, зробили в CP866.
Якщо подивитеся на найперший скріншот (базової частини, яка входить в усі розширені кодування), то помітите, що в KOI8-R російські літери розташовані в тих же елементах таблиці, що і співзвучні їм літери латинського алфавіту з першої частини таблиці. Це було зроблено для зручності переходу з російських символів на латинські шляхом відкидання всього одного біта (два в сьомий ступеня або 128).
Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
Подальший розвиток кодувань тексту було пов'язано з тим, що набирали популярність графічні операційні системи і необхідність використання псевдографіки в них з часом зникла. В результаті виникла ціла група, яка за своєю суттю і раніше були розширеними версіями Аски (один символ тексту кодується всього одним байтом інформації), але вже без використання символів псевдографіки.
Вони ставилися до так званим ANSI кодувань, які були розроблені американським інститутом стандартизації. У просторіччі ще використовувалося назву кирилиця для варіанту з підтримкою російської мови. Прикладом такої може служити Windows 1251.
Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли відсутні символи російської типографіки (окрім знака наголоси), а також символи, які використовуються в близьких до російського слов'янських мовах (українській, білоруській і т.д. ):
Через такої великої кількості кодувань російської мови, у виробників шрифтів і виробників програмного забезпечення постійно виникала головний біль, а у нас з вам, шановні читачі, часто вилазили ті самі горезвісні кракозябри, коли відбувалася плутанина з використовуваної в тексті версією.
Дуже часто вони вилазили при відправці і отриманні повідомлень по електронній пошті, що спричинило за собою створення дуже складних перекодіровочний таблиць, які, власне, вирішити цю проблему в корені не змогли, і часто користувачі для листування використовували транслит латинських букв , Щоб уникнути горезвісних кракозябрами при використанні російських кодувань подібних CP866, KOI8-R або Windows 1251.
По суті, кракозябри, вилазящіе замість російського тексту, були результатом некоректного використання кодування даного мови, яка не відповідала тій, в якій було закодовано текстове повідомлення спочатку.
Припустимо, якщо символи, закодовані за допомогою CP866, спробувати відобразити, використовуючи кодову таблицю Windows 1251, то ці самі кракозябри (безглуздий набір знаків) і вилізуть, повністю замінивши собою текст повідомлення.
Аналогічна ситуація дуже часто виникає при створення сайтів на WordPress і Joomla , Форумів або блогів, коли текст з російськими символами помилково зберігається не в тій кодуванні, яка використовується на сайті за замовчуванням, або ж не в тому текстовому редакторі, який додає в код відсебеньки невидиму неозброєним оком.
Зрештою така ситуація з безліччю кодувань і постійно вилазять кракозябрами багатьом набридла, з'явилися передумови до створення нової універсальної варіації, яка б замінила собою всі існуючі і вирішила б, нарешті, на корені проблему з появою не читав текстів. Крім цього існувала проблема мов подібних китайському, де символів мови було набагато більше, ніж 256.
Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
Ці тисячі знаків мовної групи південно-східній Азії ніяк неможливо було описати в одному байті інформації, який виділявся для кодування символів в розширених версіях ASCII. В результаті був створений консорціум під назвою Юнікод (Unicode - Unicode Consortium ) При співпраці багатьох лідерів IT індустрії (ті, хто виробляє софт, хто кодує залізо, хто створює шрифти), які були зацікавлені в появі універсального кодування тексту.
Першою варіацією, що вийшла під егідою консорціуму Юнікод, була UTF 32. Цифра в назві кодування означає кількість біт, яке використовується для кодування одного символу. 32 біта становлять 4 байта інформації, які знадобляться для кодування одного єдиного знака в новій універсальній кодуванні UTF.
В результаті чого, один і той же файл з текстом, закодований в розширеній версії ASCII і в UTF-32, в останньому випадку буде мати розмір (важити) в чотири рази більше. Це погано, але зате тепер у нас з'явилася можливість закодувати за допомогою ЮТФ число знаків, що дорівнює двом в тридцять другого ступеня (мільярди символів, які покриють будь реально необхідне значення з колосальним запасом).
Але багатьом країнам з мовами європейської групи таку величезну кількість знаків використовувати в кодуванні зовсім і не було необхідності, однак при залученні UTF-32 вони ні за що ні про що отримували чотириразове збільшення ваги текстових документів, а в результаті і збільшення обсягу інтернет трафіку і обсягу збережених даних. Це багато, і таке марнотратство собі ніхто не міг дозволити.
В результаті розвитку Юникода з'явилася UTF-16, яка вийшла настільки вдалою, що була прийнята за замовчуванням як базове простір для всіх символів, які у нас використовуються. Вона використовує два байта для кодування одного знака. Давайте подивимося, як ця справа виглядає.
В операційній системі Windows ви можете пройти по шляху «Пуск» - «Програми» - «Стандартні» - «Службові» - «Таблиця символів». В результаті відкриється таблиця з векторними формами всіх встановлених у вас в системі шрифтів. Якщо ви виберете в «Додаткових параметрах» набір знаків Юнікод, то зможете побачити для кожного шрифту окремо весь асортимент входять до нього символів.
До речі, клацнувши по будь-якому з них, ви зможете побачити його багатобайтових код у форматі UTF-16, що складається з чотирьох шістнадцятирічних цифр:
Скільки символів можна закодувати в UTF-16 за допомогою 16 біт? 65 536 (два в ступені шістнадцять), і саме це число було прийнято за базову простір в Юникоде. Крім цього існують способи закодувати за допомогою неї і близько двох мільйонів знаків, але обмежилися розширеним простором в мільйон символів тексту.
Але навіть ця вдала версія кодування Юнікоду не принесла особливого задоволення тим, хто писав, припустимо, програми тільки на англійській мові, бо у них, після переходу від розширеної версії ASCII до UTF-16, вага документів збільшувався в два рази (один байт на один символ в Аски і два байта на той же самий символ в ЮТФ-16).
Ось саме для задоволення всіх і вся в консорціумі Unicode було вирішено придумати кодування змінної довжини. Її назвали UTF-8. Незважаючи на вісімку в назві, вона дійсно має змінну довжину, тобто кожен символ тексту може бути закодований в послідовність довжиною від одного до шести байт.
На практиці ж в UTF-8 використовується тільки діапазон від одного до чотирьох байт, тому що за чотирма байтами коду нічого вже навіть теоретично не можливо уявити. Всі латинські знаки в ній кодуються в один байт, так само як і в старій добрій ASCII.
Що примітно, в разі кодування тільки латиниці, навіть ті програми, які не розуміють Юнікод, все одно прочитають те, що закодовано в ЮТФ-8. Тобто базова частина Аски просто перейшла в це дітище консорціуму Unicode.
Кириличні ж знаки в UTF-8 кодуються в два байта, а, наприклад, грузинські - в три байта. Консорціум Юнікод після створення UTF 16 і 8 вирішив основну проблему - тепер у нас в шрифтах існує єдине кодове простір. І тепер їх виробникам залишається тільки виходячи зі своїх сил і можливостей заповнювати його векторними формами символів тексту. Зараз в набори навіть емодзі смайли додають .
У наведеній трохи вище «Таблиці символів» видно, що різні шрифти підтримують різну кількість знаків. Деякі насичені символами Юнікоду шрифти можуть важити дуже пристойно. Але зате тепер вони відрізняються не тим, що вони створені для різних кодувань, а тим, що виробник шрифту заповнив або не заповнить єдине кодове простір тими чи іншими векторними формами до кінця.
Кракозябри замість російських букв - як виправити
Давайте тепер подивимося, як з'являються замість тексту кракозябри або, іншими словами, як вибирається правильна кодування для російського тексту. Власне, вона задається в тій програмі, в якій ви створюєте або редагуєте цей самий текст, або ж код з використанням текстових фрагментів.
Для редагування та створення текстових файлів особисто я використовую дуже хороший, на мій погляд, Html і PHP редактор Notepad ++ . Втім, він може підсвічувати синтаксис ще доброї сотні мов програмування і розмітки, а також має можливість розширення за допомогою плагінів. Читайте детальний огляд цієї чудової програми за посиланням.
У верхньому меню Notepad ++ є пункт «Кодування», де у вас буде можливість перетворити вже наявний варіант в той, який використовується на вашому сайті за замовчуванням:
У разі сайту на Joomla 1.5 і вище, а також в разі блогу на WordPress слід в уникненні появи кракозябрами вибирати варіант UTF 8 без BOM. А що таке приставка BOM?
Справа в тому, що коли розробляли кодування ЮТФ-16, для чогось вирішили прикрутити до неї таку річ, як можливість записувати код символу, як в прямій послідовності (наприклад, 0A15), так і в зворотному (150A). А для того, щоб програми розуміли, в якій саме послідовності читати коди, і був придуманий BOM (Byte Order Mark або, іншими словами, сигнатура), яка виражалася в додаванні трьох додаткових байтів в самий початок документів.
У кодуванні UTF-8 ніяких BOM передбачено в консорціумі Юнікод не було і тому додавання сигнатури (цих самих горезвісних додаткових трьох байтів в початок документа) деякими програмами просто-напросто заважає читати код. Тому ми завжди при збереженні файлів в ЮТФ повинні вибирати варіант без BOM (без сигнатури). Таким чином, ви заздалегідь убезпечите себе від того, що вилазить кракозябрами.
Що примітно, деякі програми в Windows не вміють цього робити (не вміють зберігати текст в ЮТФ-8 без BOM), наприклад, все той же горезвісний Блокнот Windows. Він зберігає документ в UTF-8, але все одно додає в його початок сигнатуру (три додаткових байта). Причому ці байти будуть завжди одні й ті ж - читати код в прямій послідовності. Але на серверах через цю дрібниці може виникнути проблема - вилізуть кракозябри.
Тому ні в якому разі не користуйтеся звичайним блокнотом Windows для редагування документів вашого сайту, якщо не хочете появи кракозябрами. Кращим і найбільш простим варіантом я вважаю вже згаданий редактор Notepad ++, який практично не має недоліків і складається з одних лише достоїнств.
У Notepad ++ при виборі кодування у вас буде можливість перетворити текст в кодування UCS-2, яка за своєю суттю дуже близька до стандарту Юнікод. Також в Нотепаде можна буде закодувати текст в ANSI, тобто стосовно до російської мови це буде вже описана нами трохи вище Windows 1251. Звідки береться ця інформація?
Вона прописана в реєстрі вашої операційної системи Windows - яке кодування вибирати в разі ANSI, яку обирати в разі OEM (для російської мови це буде CP866). Якщо ви встановите на своєму комп'ютері іншу мову за замовчуванням, то і ці кодування будуть замінені на аналогічні з розряду ANSI або OEM для того самого мови.
Після того, як ви в Notepad ++ збережіть документ в потрібній вам кодуванні або ж відкриєте документ з сайту для редагування, то в правому нижньому кутку редактора зможете побачити її назва:
Щоб уникнути кракозябрами, крім описаних вище дій, буде корисним прописати в його шапці вихідного коду всіх сторінок сайту інформацію про цю саму кодуванні, щоб на сервері або локальному хості не виникло плутанини.
Взагалі, у всіх мовах гіпертекстової розмітки крім Html використовується спеціальне оголошення xml, в якому вказується кодування тексту.
<? Xml version = "1.0" encoding = "windows-1251"?>
Перш, ніж почати розбирати код, браузер дізнається, яка версія використовується і як саме потрібно інтерпретувати коди символів цієї мови. Але що примітно, в разі, якщо ви зберігаєте документ в прийнятому за замовчуванням юникоде, то це оголошення xml можна буде опустити (кодування буде вважатися UTF-8, якщо немає BOM або ЮТФ-16, якщо BOM є).
У разі ж документа мови Html для вказівки кодування використовується елемент Meta, який прописується між відкриває і закриває тегом Head:
<Head> ... <meta charset = "utf-8"> ... </ head>
Ця запис досить сильно відрізняється від прийнятої в стандарті в Html 4.01 , Але повністю відповідає новому впроваджуваного потихеньку стандарту Html 5, і вона буде стовідсотково правильно зрозуміла будь-якими використовуваними на поточний момент браузерами.
За ідеєю, елемент Meta із зазначенням кодування Html документа краще буде ставити якомога вище в шапці документа, щоб на момент зустрічі в тексті першого знака не з базової ANSI (які правильно прочитали завжди і в будь-який варіації) браузер вже повинен мати інформацію про те, як інтерпретувати коди цих символів.
Удачі вам! До швидких зустрічей на страницах блогу KtoNaNovenkogo.ru
Збірки по темі
Використову для заробітку
Кодування тексту ASCII (Windows 1251, CP866, KOI8-R) і Unicode (UTF 8, 16, 32) - як виправити проблему з кракозябрами
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Сьогодні ми поговоримо з вами про те, звідки беруться кракозябри на сайті і в програмах, які кодування тексту існують і які з них слід використовувати. Детально розглянемо історію їх розвитку, починаючи від базової ASCII, а також її розширених версій CP866, KOI8-R, Windows-1251 і закінчуючи сучасними кодуваннями консорціуму Юнікод UTF 16 і 8.
Кому-то ці відомості можуть здатися зайвими, але знали б ви, скільки мені приходить питань саме стосовно вилізли кракозябрами (не читав набору символів). Тепер у мене буде можливість відсилати всіх до тексту цієї статті і самостійно відшукувати свої косяки. Ну що ж, приготуйтеся вбирати інформацію і постарайтеся стежити за ходом розповіді.
ASCII - базова кодування тексту для латиниці
Розвиток кодувань текстів відбувалося одночасно з формуванням галузі IT, і вони за цей час встигли зазнати досить багато змін. Історично все починалося з досить-таки не милозвучно в російській вимові EBCDIC, яка дозволяла кодувати літери латинського алфавіту, арабські цифри і знаки пунктуації з керуючими символами.
Але все ж відправною точкою для розвитку сучасних кодувань текстів варто вважати знамениту ASCII (American Standard Code for Information Interchange, яка по-російському звичайно вимовляється як «аски»). Вона описує перші 128 символів з найбільш часто використовуваних англомовними користувачами - латинські букви, арабські цифри і розділові знаки.
Ще в ці 128 знаків, описаних в ASCII, потрапляли деякі службові символи навроде дужок, решіток, зірочок і т.п. Власне, ви самі можете побачити їх:
Саме ці 128 символів з початкового варіант ASCII стали стандартом, і в будь-який інший кодуванні ви їх обов'язково зустрінете і стояти вони будуть саме в такому порядку.
Але справа в тому, що за допомогою одного байта інформації можна закодувати НЕ 128, а цілих 256 різних значень (двійка в ступеня вісім дорівнює 256), тому слідом за базовою версією Аски з'явився цілий ряд розширених кодувань ASCII, в яких можна було крім 128 основних знаків закодувати ще й символи національної кодування (наприклад, російської).
Тут, напевно, варто ще трохи сказати про системи числення, які використовуються при описі. По-перше, як ви всі знаєте, комп'ютер працює тільки з числами в двійковій системі, а саме з нулями і одиницями ( «булева алгебра», якщо хто проходив в інституті або в школі). Один байт складається з восьми біт , Кожен з яких представляє з себе двійку в ступені, починаючи з нульової, і до двійки в сьомий:
Не важко зрозуміти, що всіх можливих комбінацій нулів і одиниць в такій конструкції може бути тільки 256. Перекладати число з двійкової системи в десяткову досить просто. Потрібно просто скласти всі ступені двійки, над якими стоять одиниці.
У нашому прикладі це виходить 1 (2 певною мірою нуль) плюс 8 (два в ступені 3), плюс 32 (двійка в п'ятого ступеня), плюс 64 (в шостий), плюс 128 (в сьомий). Разом отримує 233 в десятковій системі числення. Як бачите, все дуже просто.
Але якщо ви придивитеся до таблиці з символами ASCII, то побачите, що вони представлені в шістнадцятковій кодуванні. Наприклад, «зірочка» відповідає в Аски шістнадцятиричним числу 2A. Напевно, вам відомо, що в шістнадцятковій системі числення використовуються крім арабських цифр ще й латинські літери від A (означає десять) до F (означає п'ятнадцять).
Ну так от, для перекладу двійкового числа в шістнадцяткове вдаються до наступного простому і наочному способу. Кожен байт інформації розбивають на дві частини по чотири біта, як показано на наведеному вище скріншоті. Т.ч. в кожній половинці байта двійковим кодом можна закодувати тільки шістнадцять значень (два в четвертого ступеня), що можна легко уявити шістнадцятковим числом.
Причому, в лівій половині байта вважати ступеня потрібно буде знову починаючи з нульової, а не так, як показано на скріншоті. В результаті, шляхом нехитрих обчислень, ми отримаємо, що на скріншоті закодовано число E9. Сподіваюся, що хід моїх міркувань і розгадка даного ребуса вам виявилися зрозумілі. Ну, а тепер продовжимо, власне, говорити про кодування тексту.
Розширені версії Аски - кодування CP866 і KOI8-R з псевдографікою
Отже, ми з вами почали говорити про ASCII, яка була як би відправною точкою для розвитку всіх сучасних кодувань (Windows 1251, юнікод, UTF 8).
Спочатку в неї було закладено тільки 128 знаків латинського алфавіту, арабських цифр і ще чогось там, але в розширеній версії з'явилася можливість використовувати всі 256 значень, які можна закодувати в одному байті інформації. Тобто з'явилася можливість додати в Аски символи букв своєї мови.
Тут потрібно буде ще раз відволіктися, щоб пояснити - навіщо взагалі потрібні кодування текстів і чому це так важливо. Символи на екрані вашого комп'ютера формуються на основі двох речей - наборів векторних форм (уявлень) всіляких знаків (вони знаходяться в файлах з шрифтами, які встановлені на вашому комп'ютері ) І коду, який дозволяє висмикнути з цього набору векторних форм (файлу шрифту) саме той символ, який потрібно буде вставити в потрібне місце.
Зрозуміло, що за самі векторні форми відповідають шрифти, а ось за кодування відповідає операційна система і які використовуються в ній програми. Тобто будь-який текст на вашому комп'ютері буде являти собою набір байтів, в кожному з яких закодований один єдиний символ цього самого тексту.
Програма, яка відображає цей текст на екрані (текстовий редактор, браузер і т.п.), при розборі коду зчитує кодування чергового знака і шукає відповідну йому векторну форму в потрібному файлі шрифту, який підключений для відображення даного текстового документа. Все просто і банально.
Значить, щоб закодувати будь-який потрібний нам символ (наприклад, з національного алфавіту), має бути виконано дві умови - векторна форма цього знака повинна бути в використовуваному шрифті і цей символ можна було б закодувати в розширених кодуваннях ASCII в один байт. Тому таких варіантів існує ціла купа. Тільки лише для кодування символів російської мови існує кілька різновидів розширеної Аски.
Наприклад, спочатку з'явилася CP866, в якій була можливість використовувати символи російського алфавіту і вона була розширеною версією ASCII.
Тобто її верхня частина повністю збігалася з базовою версією Аски (128 символів латиниці, цифр і ще всякої лабуди), яка представлена на наведеному трохи вище скріншоті, а ось вже нижня частина таблиці з кодуванням CP866 мала вказаний на скріншоті трохи нижче вид і дозволяла закодувати ще 128 знаків (російські літери і всяка там псевдографіка):
Бачите, в правій колонці цифри починаються з 8, тому що числа з 0 до 7 відносяться до базової частини ASCII (див. перший скріншот). Т.ч. російська буква «М» в CP866 матиме код 9С (вона знаходиться на перетині відповідних рядка з 9 і стовпці з цифрою С в шістнадцятковій системі числення), який можна записати в одному байті інформації, і при наявності відповідного шрифту з російськими символами ця буква без проблем відобразиться в тексті.
Звідки взялося таке кількість псевдографіки в CP866? Тут вся справа в тому, що це кодування для російського тексту розроблялася ще в ті волохаті року, коли не було такого поширення графічних операційних систем як зараз. А в Досі, і подібних їй текстових операционках, псевдографіка дозволяла хоч якось урізноманітнити оформлення текстів і тому нею рясніє CP866 і всі інші її ровесниці з розряду розширених версій Аски.
CP866 поширювала компанія IBM, але крім цього для символів російської мови були розроблені ще ряд кодувань, наприклад, до цього ж типу (розширених ASCII) можна віднести KOI8-R:
Принцип її роботи залишився той же самий, що і у описаної раніше CP866 - кожен символ тексту кодується одним єдиним байтом. На скріншоті показана друга половина таблиці KOI8-R, тому що перша половина повністю відповідає базовій Аски, яка показана на першому скріншоті в цій статті.
Серед особливостей кодування KOI8-R можна відзначити те, що російські букви в її таблиці йдуть не в алфавітному порядку, як це, наприклад, зробили в CP866.
Якщо подивитеся на найперший скріншот (базової частини, яка входить в усі розширені кодування), то помітите, що в KOI8-R російські літери розташовані в тих же елементах таблиці, що і співзвучні їм літери латинського алфавіту з першої частини таблиці. Це було зроблено для зручності переходу з російських символів на латинські шляхом відкидання всього одного біта (два в сьомий ступеня або 128).
Windows-1251 - сучасна версія ASCII і чому вилазять кракозябри
Подальший розвиток кодувань тексту було пов'язано з тим, що набирали популярність графічні операційні системи і необхідність використання псевдографіки в них з часом зникла. В результаті виникла ціла група, яка за своєю суттю і раніше були розширеними версіями Аски (один символ тексту кодується всього одним байтом інформації), але вже без використання символів псевдографіки.
Вони ставилися до так званим ANSI кодувань, які були розроблені американським інститутом стандартизації. У просторіччі ще використовувалося назву кирилиця для варіанту з підтримкою російської мови. Прикладом такої може служити Windows 1251.
Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли відсутні символи російської типографіки (окрім знака наголоси), а також символи, які використовуються в близьких до російського слов'янських мовах (українській, білоруській і т.д. ):
Через такої великої кількості кодувань російської мови, у виробників шрифтів і виробників програмного забезпечення постійно виникала головний біль, а у нас з вам, шановні читачі, часто вилазили ті самі горезвісні кракозябри, коли відбувалася плутанина з використовуваної в тексті версією.
Дуже часто вони вилазили при відправці і отриманні повідомлень по електронній пошті, що спричинило за собою створення дуже складних перекодіровочний таблиць, які, власне, вирішити цю проблему в корені не змогли, і часто користувачі для листування використовували транслит латинських букв , Щоб уникнути горезвісних кракозябрами при використанні російських кодувань подібних CP866, KOI8-R або Windows 1251.
По суті, кракозябри, вилазящіе замість російського тексту, були результатом некоректного використання кодування даного мови, яка не відповідала тій, в якій було закодовано текстове повідомлення спочатку.
Припустимо, якщо символи, закодовані за допомогою CP866, спробувати відобразити, використовуючи кодову таблицю Windows 1251, то ці самі кракозябри (безглуздий набір знаків) і вилізуть, повністю замінивши собою текст повідомлення.
Аналогічна ситуація дуже часто виникає при створення сайтів на WordPress і Joomla , Форумів або блогів, коли текст з російськими символами помилково зберігається не в тій кодуванні, яка використовується на сайті за замовчуванням, або ж не в тому текстовому редакторі, який додає в код відсебеньки невидиму неозброєним оком.
Зрештою така ситуація з безліччю кодувань і постійно вилазять кракозябрами багатьом набридла, з'явилися передумови до створення нової універсальної варіації, яка б замінила собою всі існуючі і вирішила б, нарешті, на корені проблему з появою не читав текстів. Крім цього існувала проблема мов подібних китайському, де символів мови було набагато більше, ніж 256.
Юнікод (Unicode) - універсальні кодування UTF 8, 16 і 32
Ці тисячі знаків мовної групи південно-східній Азії ніяк неможливо було описати в одному байті інформації, який виділявся для кодування символів в розширених версіях ASCII. В результаті був створений консорціум під назвою Юнікод (Unicode - Unicode Consortium ) При співпраці багатьох лідерів IT індустрії (ті, хто виробляє софт, хто кодує залізо, хто створює шрифти), які були зацікавлені в появі універсального кодування тексту.
Першою варіацією, що вийшла під егідою консорціуму Юнікод, була UTF 32. Цифра в назві кодування означає кількість біт, яке використовується для кодування одного символу. 32 біта становлять 4 байта інформації, які знадобляться для кодування одного єдиного знака в новій універсальній кодуванні UTF.
В результаті чого, один і той же файл з текстом, закодований в розширеній версії ASCII і в UTF-32, в останньому випадку буде мати розмір (важити) в чотири рази більше. Це погано, але зате тепер у нас з'явилася можливість закодувати за допомогою ЮТФ число знаків, що дорівнює двом в тридцять другого ступеня (мільярди символів, які покриють будь реально необхідне значення з колосальним запасом).
Але багатьом країнам з мовами європейської групи таку величезну кількість знаків використовувати в кодуванні зовсім і не було необхідності, однак при залученні UTF-32 вони ні за що ні про що отримували чотириразове збільшення ваги текстових документів, а в результаті і збільшення обсягу інтернет трафіку і обсягу збережених даних. Це багато, і таке марнотратство собі ніхто не міг дозволити.
В результаті розвитку Юникода з'явилася UTF-16, яка вийшла настільки вдалою, що була прийнята за замовчуванням як базове простір для всіх символів, які у нас використовуються. Вона використовує два байта для кодування одного знака. Давайте подивимося, як ця справа виглядає.
В операційній системі Windows ви можете пройти по шляху «Пуск» - «Програми» - «Стандартні» - «Службові» - «Таблиця символів». В результаті відкриється таблиця з векторними формами всіх встановлених у вас в системі шрифтів. Якщо ви виберете в «Додаткових параметрах» набір знаків Юнікод, то зможете побачити для кожного шрифту окремо весь асортимент входять до нього символів.
До речі, клацнувши по будь-якому з них, ви зможете побачити його багатобайтових код у форматі UTF-16, що складається з чотирьох шістнадцятирічних цифр:
Скільки символів можна закодувати в UTF-16 за допомогою 16 біт? 65 536 (два в ступені шістнадцять), і саме це число було прийнято за базову простір в Юникоде. Крім цього існують способи закодувати за допомогою неї і близько двох мільйонів знаків, але обмежилися розширеним простором в мільйон символів тексту.
Але навіть ця вдала версія кодування Юнікоду не принесла особливого задоволення тим, хто писав, припустимо, програми тільки на англійській мові, бо у них, після переходу від розширеної версії ASCII до UTF-16, вага документів збільшувався в два рази (один байт на один символ в Аски і два байта на той же самий символ в ЮТФ-16).
Ось саме для задоволення всіх і вся в консорціумі Unicode було вирішено придумати кодування змінної довжини. Її назвали UTF-8. Незважаючи на вісімку в назві, вона дійсно має змінну довжину, тобто кожен символ тексту може бути закодований в послідовність довжиною від одного до шести байт.
На практиці ж в UTF-8 використовується тільки діапазон від одного до чотирьох байт, тому що за чотирма байтами коду нічого вже навіть теоретично не можливо уявити. Всі латинські знаки в ній кодуються в один байт, так само як і в старій добрій ASCII.
Що примітно, в разі кодування тільки латиниці, навіть ті програми, які не розуміють Юнікод, все одно прочитають те, що закодовано в ЮТФ-8. Тобто базова частина Аски просто перейшла в це дітище консорціуму Unicode.
Кириличні ж знаки в UTF-8 кодуються в два байта, а, наприклад, грузинські - в три байта. Консорціум Юнікод після створення UTF 16 і 8 вирішив основну проблему - тепер у нас в шрифтах існує єдине кодове простір. І тепер їх виробникам залишається тільки виходячи зі своїх сил і можливостей заповнювати його векторними формами символів тексту. Зараз в набори навіть емодзі смайли додають .
У наведеній трохи вище «Таблиці символів» видно, що різні шрифти підтримують різну кількість знаків. Деякі насичені символами Юнікоду шрифти можуть важити дуже пристойно. Але зате тепер вони відрізняються не тим, що вони створені для різних кодувань, а тим, що виробник шрифту заповнив або не заповнить єдине кодове простір тими чи іншими векторними формами до кінця.
Кракозябри замість російських букв - як виправити
Давайте тепер подивимося, як з'являються замість тексту кракозябри або, іншими словами, як вибирається правильна кодування для російського тексту. Власне, вона задається в тій програмі, в якій ви створюєте або редагуєте цей самий текст, або ж код з використанням текстових фрагментів.
Для редагування та створення текстових файлів особисто я використовую дуже хороший, на мій погляд, Html і PHP редактор Notepad ++ . Втім, він може підсвічувати синтаксис ще доброї сотні мов програмування і розмітки, а також має можливість розширення за допомогою плагінів. Читайте детальний огляд цієї чудової програми за посиланням.
У верхньому меню Notepad ++ є пункт «Кодування», де у вас буде можливість перетворити вже наявний варіант в той, який використовується на вашому сайті за замовчуванням:
У разі сайту на Joomla 1.5 і вище, а також в разі блогу на WordPress слід в уникненні появи кракозябрами вибирати варіант UTF 8 без BOM. А що таке приставка BOM?
Справа в тому, що коли розробляли кодування ЮТФ-16, для чогось вирішили прикрутити до неї таку річ, як можливість записувати код символу, як в прямій послідовності (наприклад, 0A15), так і в зворотному (150A). А для того, щоб програми розуміли, в якій саме послідовності читати коди, і був придуманий BOM (Byte Order Mark або, іншими словами, сигнатура), яка виражалася в додаванні трьох додаткових байтів в самий початок документів.
У кодуванні UTF-8 ніяких BOM передбачено в консорціумі Юнікод не було і тому додавання сигнатури (цих самих горезвісних додаткових трьох байтів в початок документа) деякими програмами просто-напросто заважає читати код. Тому ми завжди при збереженні файлів в ЮТФ повинні вибирати варіант без BOM (без сигнатури). Таким чином, ви заздалегідь убезпечите себе від того, що вилазить кракозябрами.
Що примітно, деякі програми в Windows не вміють цього робити (не вміють зберігати текст в ЮТФ-8 без BOM), наприклад, все той же горезвісний Блокнот Windows. Він зберігає документ в UTF-8, але все одно додає в його початок сигнатуру (три додаткових байта). Причому ці байти будуть завжди одні й ті ж - читати код в прямій послідовності. Але на серверах через цю дрібниці може виникнути проблема - вилізуть кракозябри.
Тому ні в якому разі не користуйтеся звичайним блокнотом Windows для редагування документів вашого сайту, якщо не хочете появи кракозябрами. Кращим і найбільш простим варіантом я вважаю вже згаданий редактор Notepad ++, який практично не має недоліків і складається з одних лише достоїнств.
У Notepad ++ при виборі кодування у вас буде можливість перетворити текст в кодування UCS-2, яка за своєю суттю дуже близька до стандарту Юнікод. Також в Нотепаде можна буде закодувати текст в ANSI, тобто стосовно до російської мови це буде вже описана нами трохи вище Windows 1251. Звідки береться ця інформація?
Вона прописана в реєстрі вашої операційної системи Windows - яке кодування вибирати в разі ANSI, яку обирати в разі OEM (для російської мови це буде CP866). Якщо ви встановите на своєму комп'ютері іншу мову за замовчуванням, то і ці кодування будуть замінені на аналогічні з розряду ANSI або OEM для того самого мови.
Після того, як ви в Notepad ++ збережіть документ в потрібній вам кодуванні або ж відкриєте документ з сайту для редагування, то в правому нижньому кутку редактора зможете побачити її назва:
Щоб уникнути кракозябрами, крім описаних вище дій, буде корисним прописати в його шапці вихідного коду всіх сторінок сайту інформацію про цю саму кодуванні, щоб на сервері або локальному хості не виникло плутанини.
Взагалі, у всіх мовах гіпертекстової розмітки крім Html використовується спеціальне оголошення xml, в якому вказується кодування тексту.
<? Xml version = "1.0" encoding = "windows-1251"?>
Перш, ніж почати розбирати код, браузер дізнається, яка версія використовується і як саме потрібно інтерпретувати коди символів цієї мови. Але що примітно, в разі, якщо ви зберігаєте документ в прийнятому за замовчуванням юникоде, то це оголошення xml можна буде опустити (кодування буде вважатися UTF-8, якщо немає BOM або ЮТФ-16, якщо BOM є).
У разі ж документа мови Html для вказівки кодування використовується елемент Meta, який прописується між відкриває і закриває тегом Head:
<Head> ... <meta charset = "utf-8"> ... </ head>
Ця запис досить сильно відрізняється від прийнятої в стандарті в Html 4.01 , Але повністю відповідає новому впроваджуваного потихеньку стандарту Html 5, і вона буде стовідсотково правильно зрозуміла будь-якими використовуваними на поточний момент браузерами.
За ідеєю, елемент Meta із зазначенням кодування Html документа краще буде ставити якомога вище в шапці документа, щоб на момент зустрічі в тексті першого знака не з базової ANSI (які правильно прочитали завжди і в будь-який варіації) браузер вже повинен мати інформацію про те, як інтерпретувати коди цих символів.
Удачі вам! До швидких зустрічей на сторінках блогу KtoNaNovenkogo.ru
Збірки по темі
Використовую для заробітку
А що таке приставка BOM?1251. Звідки береться ця інформація?
Lt;?
Encoding = "windows-1251"?
А що таке приставка BOM?
1251. Звідки береться ця інформація?
Lt;?
Encoding = "windows-1251"?