- команда top
- Середнє навантаження на систему (load average)
- параметр Cpu
- Навантаження на процесор (параметри sy, us, ni)
- Приклад діагностики проблем при високому us і sy
- Визначення оверселлінг (параметр st)
- Навантаження введення-виведення (параметр wa)
- Приклад знаходження причин високого wa і load average
- Навантаження введення-виведення: копаємо глибше (atop)
- висновок
Віртуальна машина не завжди працює з очікуваною швидкістю. Сайт раптово починає гальмувати, скрипти виконуються довго. У цій статті ми покажемо яким чином можна аналізувати продуктивність віртуальної машини і знаходити причини вповільнень в роботі.
У центрі нашої уваги будуть навантаження, пов'язані з використанням центрального процесора і жорсткого диска.
Постараємося відповісти на питання: що робити в разі проблем на сервері, які інструменти використовувати і на що звертати увагу для діагностування проблем продуктивності в операційній системі Linux.
команда top
Головним інструментом у цій справі стане команда top . Результат її виконання виглядає так:
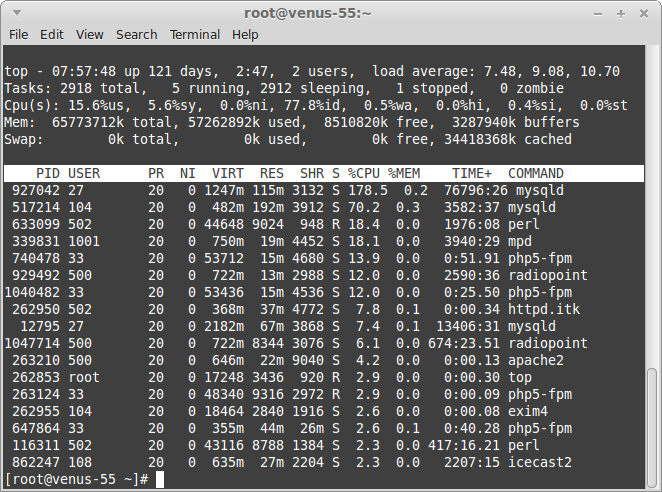
Програма top видає динамічне представлення про працюючій системі в реальному часі. Верхню частину виведення займає коротка узагальнена інформація, нижню частину - список запущених процесів.
Розглянемо основні показники, які можуть нас зацікавити.
Середнє навантаження на систему (load average)

Load Average - середнє значення завантаженості системи за період часу (в подальшому LA). Три значення показують усереднену навантаження за останні 1, 5 і 15 хвилин. LA є одним з найбільш спірних показників. Можна знайти безліч суперечливих статей, яке значення вважати нормальним. Зазвичай приймається, що значення 0 це простий ядра, а значення 1 це повне навантаження ядра. Оцінити показник середньої навантаження можна тільки знаючи кількість ядер в системі. Дізнатися скільки ядер є можна командою:
dmidecode -t processor | grep "Core Enabled:" Core Enabled: 6 Core Enabled: 6
Бачимо, що на даній системі знаходиться 12 фізичних ядер (6 + 6). Відповідно, нормальний показник LA повинен бути менше 12. Проте, на процесорах Intel використовується технологія Hyper-Threading , Яка ділить одне фізичне ядро на два логічних.
dmidecode -t processor | grep "Thread Count:" Thread Count: 12 Thread Count: 12
Відповідно, в даному випадку в системі може бути одночасно 24 віртуальних процесора (потоку).
технологія Turbo Boost дозволяє процесору «розганятися» і працювати на частоті вище заявленої (тобто вище 100%, вище одиниці). Який показник LA вважати нормальним в даному випадку є предметом суперечок.
Були спроби обчислити нормальне значення LA емпіричним шляхом . Але ми вважаємо це безглуздим заняттям. Справа в тому, що в LA потрапляють також процеси, що стоять в черзі читання / запису і не мають відношення до процесору, а також процеси з пріоритетом, зміненим за допомогою команди nice . У разі якщо команда запущена з низьким пріоритетом, вона буде знаходиться в черзі, але не буде впливати на реальну продуктивність.
Високий LA може сигналізувати про будь-які проблеми. З іншого боку, високе значення не обов'язково говорить про наявність проблем. Покладатися в діагностиці тільки на LA можна, його значення потрібно враховувати тільки спільно з іншими значеннями. Тому переходимо до наступної цікавить нас рядку: Cpu.
параметр Cpu

Рядок Cpu показує відразу декілька параметрів навантаження:
us
(user) Використання процесора призначеним для користувача процесами sy (system) Використання процесора системним процесами ni (nice) Використання процесора процесами зі зміненим пріоритетом за допомогою команди nice id (idle) Простий процесора. Можна сказати, що це вільні ресурси wa (IO-wait) Каже про просте, пов'язаних з введенням / висновком hi (hardware interrupts) Показує скільки процесорного часу було витрачено на обслуговування апаратного переривання si (software interrupts) Показує скільки процесорного часу було витрачено на обслуговування софтверного переривання st (stolen by the hypervisor) Показує скільки процесорного часу було «вкрадено» гіпервізором
Не будемо заглиблюватися в аналіз значень hi і si в цій статті, оскільки проблеми з перериваннями зустрічаються дуже рідко. Скажемо тільки, що найбільш ймовірна причина високих значень даних параметрів - проблема з кодом, ядром або DDoS-атака.
Розглянемо докладніше інші параметри СPU.
Навантаження на процесор (параметри sy, us, ni)
Високі значення sy, us і ni самі зрозумілі і прості для діагностики, оскільки показують навантаження на CPU, створювану запущеними програмами. Дивимося в виведенні команди top процеси по стовпцю% CPU і оптимізуємо їх при необхідності. Або просто додаємо потужність CPU на сервер.
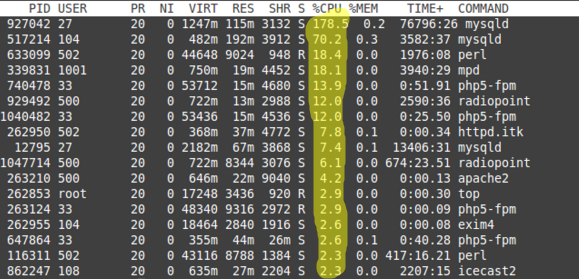
Однак треба враховувати, що однопоточні процеси будуть виконуватися тільки на одному ядрі. У цьому випадку навіть при невисокому загальному us можуть спостерігатися проблеми.
Також потрібно додати, що високе значення ni не завжди буде мати негативний вплив на працездатність сервера. Можливо, пріоритет процесів був знижений спеціально, щоб вони виконувалися тільки в тому випадку, коли процесор буде вільний. Дані процеси не впливають на роботу системи. Наприклад, це можуть бути процеси створення бекапів.
Приклад діагностики проблем при високому us і sy
На сервері top показує наступні значення:
CPU: 21.0% user, 0.0% nice, 74.6% system, 0.0% interrupt, 4.4% idle PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 95383 mysql 37 4 0 227M 74388K sbwait 1 0:00 49.80% mysqld 96904 qhost 1 97 0 171M 31884K CPU1 1 0:04 7.08% httpd 97360 frekbok 1 97 0 185M 42464K RUN 0 0:02 7.08% httpd 97442 frekbok 1 97 0 178M 37196K RUN 2 0:01 5.18% httpd 97423 frekbok 1 -4 0 178M 37160K RUN 1 0:01 4.79% httpd 97439 frekbok 1 97 0 178M 37052K RUN 2 0:01 4.79% httpd 97411 frekbok 1 -4 0 178M 37148K RUN 3 0:01 4.69% httpd 97418 frekbok 1 97 0 178M 37168K RUN 0 0 : 01 4.59% httpd 97444 frekbok 1 -4 0 178M 37192K RUN 1 0:01 4.59% httpd 97416 frekbok 1 -4 0 178M 37052K RUN 2 0:01 4.49% httpd 97421 frekbok 1 -4 0 178M 37060K CPU0 0 0:01 4.39% httpd 97424 frekbok 1 97 0 178M 37304K RUN 2 0:01 4.30% httpd
При цьому LA більше 100.
Явно видно, що проблеми в нестачі CPU для роботи mysql, і у великій кількості http-з'єднань користувача frekbok.
Заходимо до користувача frekbok і дивимося лог apache. Там бачимо такі POST-запити, і безліч їм подібних:
76.164.234.170 - - [18 / Sep / 2015: 06: 10: 41 +0400] "POST / component / k2 / HTTP / 1.0" 200 59 "Mozilla / 5.0 (Windows NT 6.1; Trident / 7.0; rv: 11.0) like Gecko "76.164.234.170 - - [18 / Sep / 2015: 06: 10: 41 +0400]" POST / component / k2 / HTTP / 1.0 "200 59" Mozilla / 5.0 (Windows NT 6.1; Trident / 7.0; rv : 11.0) like Gecko "76.164.234.170 - - [18 / Sep / 2015: 06: 10: 43 +0400]" POST / component / k2 / HTTP / 1.0 "200 59" Mozilla / 5.0 (Windows NT 6.1; Trident / 7.0; rv: 11.0) like Gecko "
За результатом аналізу логів можна зробити висновок, що проблема в китайських ботах, які постять рекламу в коментарі на сайті. Ставимо капчу на коментування або відключаємо коментарі, чистимо БД. Проблема вирішена.
Визначення оверселлінг (параметр st)
Параметр st цікавий для віртуальних машин. Можна сказати, що він відображає оверселлінг CPU на батьківської ноді. Він буде відрізнятися від 0 у разі, якщо VDS потрібно процесор, але гипервизор не може виділити CPU, так як він використовується в даний момент іншими VDS. У разі, якщо цей параметр приймає великі значення на вашій VDS (орієнтовно понад 5-10% спільно з високим LA) і це заважає вашій роботі, то залишається тільки написати в техпідтримку з проханням перенести VDS на іншу ноду.
Навантаження введення-виведення (параметр wa)
Найцікавіший показник це wa. На сучасних серверах потужності процесора і пам'яті зазвичай вистачає, а більшість проблем пов'язані з операціями вводу / виводу.
Високі значення wa, а також високий LA, зазвичай говорять про просте процесів в стані D-state, пов'язаному з дисковою підсистемою або з мережевими проблемами. Однак, не можна забувати, що цей параметр відноситься до всіх операцій введення / виводу. Наприклад, на виділеному сервері це значення може вирости при роботі з USB-накопичувачем, очікуванні відповіді від сокета або бути викликана іншими причинами.
Спрощена модель станів в Linux
- D -state - стан безперервного сну (процеси, які очікують звільнення потоку введення-виведення)
- R -state - процес активний в даний час (виконується в даний момент)
- S -state - стані очікування (sleeping), тобто він очікує якоїсь події або сигналу
- Т -state - процес призупинено сигналом STOP або виконанням трасування
- Z -state - «зомбі», процес, який завершив своє виконання, але присутній в системі, щоб дати батьківського процесу вважати свій код завершення
Подивитися стан процесів в системі можна за допомогою команди ps з опціями: ps aux
За практичного досвіду, помітні проблеми починаються при wa більше 10-30%. Потрібно розуміти, що велике значення цього параметра не завжди свідчить про проблеми. Але бажано встановити причину такої поведінки і по можливості виправити ситуацію.
Приклад знаходження причин високого wa і load average
Дивимося командою ps aux | grep D процеси в стані D.
102 628884 0.0 0.0 97308 2432? D 13:08 0:00 / usr / sbin / exim4 -bd -q30m 102 628885 0.0 0.0 97308 2432? D 13:08 0:00 / usr / sbin / exim4 -bd -q30m 102 628886 0.0 0.0 97308 2432? D 13:08 0:00 / usr / sbin / exim4 -bd -q30m 102 628887 0.0 0.0 97308 2424? D 13:08 0:00 / usr / sbin / exim4 -bd -q30m 102 628888 0.0 0.0 97308 2424? D 13:08 0:00 / usr / sbin / exim4 -bd -q30m 102 628890 0.0 0.0 97308 2424? D 13:08 0:00 / usr / sbin /
Бачимо, що в стані очікування висить безліч процесів exim4. Швидше за все сервер був зламаний і з нього масово розсилають спам. Зупиняємо exim і знаходимо джерело розсилки.
У разі, якщо у вас кілька VDS на ноді і необхідно знайти джерело навантаження, потрібно знайти ту, з якої розсилається спам. Для цього можна використовувати команду tcpdump -n | grep "smtp", за допомогою неї ми проаналізуємо поштовий трафік на порту 25, і виявимо IP-адреса з якого виконується розсилка спаму.
Потрібно знати, що високий wa всередині VDS, не завжди означає проблеми всередині контейнера. Проблеми також можливі на «батьківської» ноді. Наприклад, на ній не вистачає I / O диска для всіх VDS. Тому ваші процеси потрапляють в стан очікування. У такому випадку потрібно створити тікет в тих підтримку.
Навантаження введення-виведення: копаємо глибше (atop)
Зручний інструмент для визначення причин навантаження - це atop c опціями: atop -l -c -d1
Однак, подальше опис в першу чергу буде відноситься до VDS на віртуалізації KVM і виділеним серверам. На віртуалізації OpenVZ ми не зможемо скористатися повними можливості даної утиліти, і швидше за все вам доведеться звернутися в тех. підтримку.
Розглянемо його висновок:
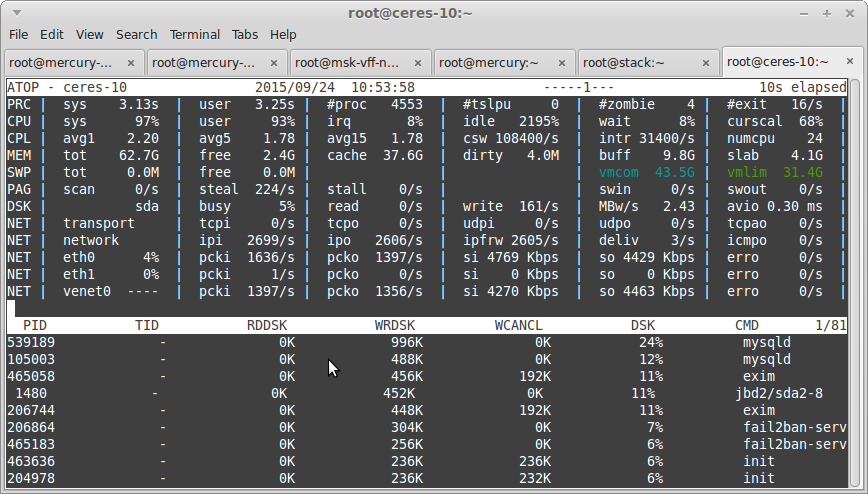
У рядку DSK ми бачимо використання диска в даний момент. У рядку busy у відсотках вказується приблизно скільки «ресурсів» диска споживається в даний момент. Якщо там буде значення близько 100% означає на диску, швидше за все, спостерігаються проблеми з операціями вводу / виводу. У разі використання VDS, цього рядка може не бути і лякатися не варто.
У нижній частині бачимо список процесів, які в даний момент виконують дискові операції. Вгорі списку будуть процеси, які споживають найбільше ресурсів.
Як ми бачимо, процес з ідентифікатором pid 539189 в даний момент веде активну запис на диск. Дізнатися в які файли пише дані цей процес можна за допомогою команди lsof .
Виклик команди lsof -p539189 (підставляємо pid-ідентифікатор потрібного процесу) показав такий результат:
mysqld 539189 110 4u REG 182,374993 0 12516 (deleted) / tmp / ib30lihW lsof: no pwd entry for UID 110 mysqld 539189 110 5u REG 182,374993 0 12520 (deleted) / tmp / ibSrHvsH lsof: no pwd entry for UID 110 mysqld 539189 110 6u REG 182,374993 0 12522 (deleted) / tmp / ibLkoJDs lsof: no pwd entry for UID 110 mysqld 539189 110 7u REG 182,374993 0 12524 (deleted) / tmp / ibNk007Y
Видно, що даний процес mysql пише тимчасові файли на жорсткий диск і цим створює навантаження. Тому бажано провести його оптимізацію.
Більш детально проаналізувати навантаження на дискову систему можна також за допомогою спеціалізованої утиліти iotop .
висновок
У даній статті ми розповіли про малу частину коштів для моніторингу навантаження на серверах. І навіть в них ми охопили мінімум можливостей. Для більш повного знайомства з можливостями описаних утиліт, читайте документацію (посилання в статті на назвах команд). Але навіть описаних в статті можливостей вистачає для діагностики більшості проблем, що виникають.