- мовні ВМ
- Два сімейства мовних ВМ
- стекові ВМ
- приклади
- Історичні важливі приклади стекових мовних ВМ
- Актуальні мовні ВМ
- реєстрові ВМ
- приклади
- екзотичні ВМ
- способи виконання
- Системні ВМ
- Класифікація системних ВМ
- способи виконання
- Підсумки
- література
На відміну від більшості модних комп'ютерних слівець, це поняття зазвичай відповідає своєму словниковому визначенню в тих випадках, коли мова йде про апаратуру або програмах. Словник «Random House College Dictionary» визначає «virtual» як «проявляє властивості і ефекти чого-небудь, але не є таким насправді».
оригінал
Virtual. Unlike most computer buzzwords, this one usually holds true to its dictionary definition when it refers to hardware or software. The Random House College Dictionary defines «virtual» as «being such in force or effect, though not actually or expressly such.» [4]
Останні кілька років на початку кожного семестру я даю студентам визначення основних термінів, які використовуються в моєму курсі: симуляція, емуляція і віртуалізація. І кожен раз я говорю, щоб мої слова не приймали за стовідсоткову правду. Справа в тому, що в одних областях технічного знання ці терміни часто трактуються протилежно тому, що прийнято використовувати в інших. Нелегке це справа - давати визначення.
Мабуть, цю проблему помітив не тільки я. У своїй книзі Software and System Development using Virtual Platforms , Що вийшла в минулому році, мої колеги Jakob Engblom і Daniel Aarno в першому розділі вводять поняття simulation і emulation і відзначають неоднозначність їх тлумачення в областях розробки програмного забезпечення і проектування апаратури.
З безладом в тлумаченні цих двох термінів я для себе розібрався і начебто змирився. Залишилося ще одне поняття, вже більше десяти (насправді п'ятдесяти) років не втрачає популярності - це «віртуалізація». За час свого буття в категорії «buzzword» воно стало поєднуватися з безліччю інших слів. Нещодавно я усвідомив, що термін «віртуальна машина» (ВМ) насправді використовується для позначення двох хоч і пов'язаних, але різних сутностей. У цій статті я розповім про двох класах: мовні і системні віртуальні машини. Я покажу подібності та відмінності між ними, їх призначення, класифікацію, загальні і приватні риси в їх практичній реалізації. 
Якщо говорити широко, то віртуальна машина - це програма, завдання якої полягає в реалізації специфікацій певного обчислювального пристрою або класу пристроїв. У цьому її головна відмінність від «просто» фізичної машини, що реалізує те ж саме, але в апаратурі. Будь-яка специфікація (архітектура комп'ютера) найчастіше включає в себе визначення інтерфейсів пристроїв і опис переходів між станами машини. Однак визначення інтерфейсу, як відомо, не повинно створювати обмежень на способи його реалізації.
Багато з нас, напевно, не помічають, як часто щодня вони стикаються з обома типами машин - віртуальними і реальними. Наприклад, найпростіший калькулятор має дві реалізації - як спеціалізований пристрій і як програма: 
І апаратна машина зліва, і віртуальна машина праворуч надають один і той же інтерфейс - кнопки і екран, - і реалізують одні й ті ж функції - арифметичні, логічні, тригонометричні операції над числами в усіх розділах.
Віртуальний калькулятор - це приклад віртуальної машини - програмної копії того, що спочатку існувало тільки у вигляді апаратури, фізичної машини, цілком конкретної і відчутної системи. До системних ВМ ми повернемося трохи пізніше.
мовні ВМ
Інший випадок - це коли програма створюється для чогось «нереального» з самого початку, наприклад, для мови програмування або середовища виконання (runtime environment). У цьому випадку така мовна віртуальна машина буде способом реалізації специфікації мови або середовища.
Чи завжди потрібна ВМ?
Ключова фраза в попередньому параграфі - спосіб реалізації. Крім ВМ, є й інші способи.
Всякий раз, коли ми беремо в руки документацію на нову мову програмування, ми відкриваємо опис «неіснуючої» машини. Наприклад, K & R Сі - це в багатьох своїх місцях навмисне недомовлене опис середовища для програм на Сі. Більшість реалізацій Сі є компіляторами (буду вдячний, якщо мені підкажуть реалізації, засновані на ВМ). Для Java опис середовища і її кордонів більш чітке (у її авторів були інші цілі і завдання, ніж у творців Сі), однак і тут не диктується ні використання якоїсь конкретної ВМ (на вибір машини від Sun / Oracle, IBM, Microsoft, Apple, GNU і навіть Dalvik від Google), ні навіть необхідність в ВМ (компілятор GNU GCJ).
Мовні ВМ зазвичай проектуються для виконання одного гостьового додатки (іноді многопоточного) в одній копії віртуального середовища. Іншими словами, вони не беруть на себе типові для багатокористувацької / багатозадачною операційної системи функції розмежування доступу до ресурсів. Завдання мовної ВМ - надати програмі оточення, безпосередньо не залежить від деталей (і в якійсь мірі обмежень) нижележащей фізичної системи, таких як використовувані в останній процесори, обсяги ОЗУ і дисків, наявність і особливості периферійних пристроїв і т.д.
Звичайно ж, і тут не обійтися без холівара про термінологію. До мовних ВМ (language VMs) я буду відносити і те, що називається process virtual machine, і те, що іменується managed runtime environment (MRE).
Два сімейства мовних ВМ
Мовна ВМ стоїть на середині шляху: від мов високого рівня до машинних кодів того комп'ютера, на якому вона виконується. Тому при створенні нової архітектури мовної ВМ слід враховувати два фактори: зручність перетворення обраних вхідних мов і швидкість виконання на конкретних апаратних системах. Від першого буде залежати універсальність і розширюваність створюваної середовища, а від другого - верхня межа швидкості роботи програм для цієї ВМ.
Базовою одиницею виконання для ВМ є машинна інструкція. Кожна така інструкція повинна визначати операцію, виконувану над даними, а також місце розташування самих даних. Природно, що набір операцій сильно залежить від конкретної ВМ і може варіюватися в широких межах. «Залізні» набори інструкцій в цьому куди більш обмежені [Я все ще чекаю процесор з апаратними malloc () і free (), а краще - з апаратним складальником сміття].
З іншого боку, в підходах до організації оброблюваних даних серед ВМ не так багато різноманітності. Фактично є дві усталені концепції - зберігати дані на стек (стеках) і використовувати виділений набір регістрів.
стекові ВМ
Такі ВМ зберігають всі або майже всі дані в одному або декількох стеках. Для звернення до них використовується адресація відносного положення необхідного елементу від поточної вершини стека. Якщо у операції є результат, то він поміщається в стек, стаючи його новою вершиною. Крім даних, в стеку можуть зберігатися адреси, використовувані при поверненні з викликаних подпроцедур в викликають. Або ж адреси можуть бути в окремому стеку.
Про стекові машини відомо і написано багато, і я не буду намагатися тут описати все, що знаю і чого не знаю. Виділю лише деякі ключові факти.
Зазначу гідності стекових мовних ВМ:
- Простота трансляції виразів з інфіксной нотації (вирази зі скобочки: a + b * (c / (d - f))) в стекового уявлення (зворотний польський запис).
- Компактність кодування інструкцій. Більшість машинних команд не вимагають явних аргументів, так як вони працюють з вершиною стека.
Єдине важливе на практиці виключення - це передача в процес обчислення литералов - констант. Їх легше передати цілком у потоці інструкцій, ніж намагатися «сконструювати» з добра, вже зберігається на стеку. Але при бажанні можна зробити ВМ і без цього: завести операцію «покласти в стек одиницю», а далі складати її з собою до отримання потрібного числа.
Не можна сказати, що в стековой ВМ зовсім не може бути виділених регістрів. Як мінімум два осередки мати доводиться: одну для покажчика поточної команди, а іншу - для покажчика на вершину стека. Однак вони не завжди доступні для прямої маніпуляції в програмі, тобто не кожна машина робить їх архітектурно видимими.
Оскільки мова зараз тільки про програмних системах, я не буду заглиблюватися в особливості апаратних стекових машин, з їх сильними і слабкими сторонами, такими як обробка переривань, швидкість доступів до пам'яті, взаємодія з різними вузлами процесора, можливості до паралелізації і т.д. Рекомендую хорошу статтю на Вікіпедії в якості відправної точки.
приклади
Я не приховаю правду, сказавши, що за весь час всіляких мовних віртуальних машин було створено дуже багато. Намагатися описати їх все - безнадійна затія. Тому я далі згадаю лише деякі з них в якості прикладів.
Історичні важливі приклади стекових мовних ВМ
SECD
- абстрактна машина, що з'явилася в 1960-х роках і яка вплинула на розвиток функціональних мов, в тому числі LISP.
P-code - мова віртуальної машини, в який транслював програми перший компілятор Паскаля університету Каліфорнії. Завдяки переносимості p-code і підходу з «самораскруткой» (bootstrapping) компілятора була можливість досить швидко отримати працюючий компілятор Паскаля на нових ЕОМ, що за часів відсутності стандартів на оточення (ніяких тобі POSIX в 70-х) і величезного числа несумісних між собою архітектур ЕОМ було важливим фактором для завоювання мовою популярності.
Forth - взагалі-то Forth не можна назвати тільки мовної ВМ. Для кого-то це процедурний мову високого рівня, для кого-то об'єктно-орієнтована мова, комусь - функціональний, кому-то - машинний, а кому-то і зовсім філософія проектування систем (Thinking Forth). Однак саме Форт спадає мені на думку, коли хтось вимовляє слова «програмування» і «стек» в одному реченні.
Актуальні мовні ВМ
Java VM
- байткод для всім відомого «compile once, run everywhere» мови Java (а також для Scala, Clojure і ін.) Виконується на стековой ВМ. Сам стек зберігає скалярні дані виконуються методів, аргументи інструкцій, в тому числі посилання на об'єкти і масиви, які зберігаються в окремій області-купі.
Common Intermediate Language від Microsoft - підстава .NET-фреймворка. У нього транслюються C #, F #, VB.NET і безліч інших менш популярних мов високого рівня. Байткод виконується на стековой ВМ. Структура як середовища виконання, так і байткода CIL істотно відрізняється від JVM; в [1] наводиться їх порівняння, в тому числі показуються їх подібності між собою і відмінності від звичайних апаратних наборів інструкцій.
Таким чином, дві найпопулярніші середовища часу виконання використовують стекові мовні ВМ. Можливо, у читача виникло питання: якщо код з байткода найчастіше в кінці кінців транслюється в даний машинний код хазяйської системи, архітектура якої містить регістри, а не тільки стек (хто читає ці рядки з дисплея машини зі стековой машинною архітектурою - підніміть руки!) , то чому дві найпопулярніших мовних ВМ використовують стекового уявлення? В [1] наводиться наступний аргумент: «... a stack is amenable to platform independence (the host platform can have any number of registers in its ISA)» - «стек полегшує забезпечення платформонезавісимость (хазяйська платформа може мати будь-яку кількість регістрів в своєму наборі команд) ».
реєстрові ВМ
Альтернативний підхід до зберігання оброблюваних даних полягає у використанні виділеного набору елементів пам'яті з фіксованими іменами-номерами - регістрами. Інструкції в основному оперують з даними на регістрах, при необхідності завантажуючи відсутні значення з пам'яті або вивантажуючи непотрібні в пам'ять.
У деяких реєстрових архитектурах стек теж зазвичай є в наявності. Однак він не грає центральну роль в роботі ВМ, а використовується для підтримки процедурного механізму (і в такому випадку не обов'язково є безпосередньо доступним програмами).
Особливості реєстрових ВМ найпростіше побачити, порівнюючи їх з стековими.
- Їх машинні інструкції довше, так як в них доводиться кодувати операнди. У стекових ВМ операнди задаються неявно.
- При роботі ВМ відбувається менше число звернень до пам'яті. Стекові ВМ змушені постійно перекладати дані на стек, так як час життя останніх невелика (найчастіше операція «з'їдає» вхідні значення з вершини стека і заміщає їх своїм результатом). Значення, поміщене в регістр, живе до моменту його перезапису. Наприклад, це дозволяє позбутися від постійного обчислення або подгрузки з пам'яті значень для циклових інваріантів - вони просто розміщуються в регістрах.
- Необхідність використання алгоритмів розподілу регістрів при трансляції з мов високого рівня. Для нетривіальних програм завжди виникатиме ситуація нестачі регістрів (їх кількість обмежена) для розміщення всіх використовуваних при обчисленні даних. При цьому якось треба стежити, на якому регістрі що знаходиться в кожен момент часу. Тоді як в разі стекових ВМ вершина стека одна, і вона завжди «доступна». Ці обставини можуть значно ускладнювати логіку роботи інструментів для реєстрової ВМ.
Дуже цікаве питання полягає в тому, який тип ВМ - стековий або регістровий - виконує програми швидше. Однозначної відповіді на цей момент немає; дані одних дослідників доводять перевагу першого виду, тоді як інші стверджують зворотне. Цікавий експеримент описаний в [3] - автори статті використовують для виконання реєстрову ВМ, код для якої виходить за допомогою оптимізує трансляції з Java байткода, і порівнюють продуктивність.
приклади
Parrot VM
- довгобуд ВМ, що розробляється вже більше 10 років і служить основним середовищем виконання мови Perl 6.
Dalvik від Google - реєстрова ВМ, що служить для виконання програм, написаних на Java. Цікаво, що байткод стековой JVM (* .class) перетворюється в байткод реєстрової ВМ (* .dex). В даний час Dalvik відходить на другий план в Android, поступаючись місцем ART - механізмом прямої компіляції в машинний код хазяйської системи.
LLVM bitcode - одну з вистав вихідної програми, що використовується при трансляції програм за допомогою інструментів на основі LLVM, і за сумісництвом вхідна мова ВМ, що використовує трёхоперандний формат інструкцій з регістрами. Незвичайним в цій ВМ є те, що інструкції виражені в т.зв. SSA (single static assignment) формі, тобто вони використовують потенційно необмежену кількість віртуальних регістрів. Розподіл регістрів ВМ на фізичні відбувається пізніше в процесі трансляції в машинний код або інтерпретації.
MIX і MMIX - віртуальні машини, використовувані (або плануються до використання в майбутніх виданнях) Д. Кнутом в своїй серії книг «Мистецтво програмування» для ілюстрації реалізації алгоритмів. MIX виконана в дусі 1960-х: виділений регістр-акумулятор, 6-бітові байти, двійковій-десятковий формат чисел, відсутність стека і схильність до задіяння самомодіфіцірующіеся коду. MMIX - це вже нормальний RISC з щедрим числом (256) і шириною (64 біт) регістрів.
Про ілюстрації алгоритмів машинним кодом
Особисто мені дуже складно зрозуміти «алгоритми», написані на MIX, в і без того складної книзі безсумнівно шанованого мною автора. Мені чомусь здається, що використання мов більш високого рівня значно полегшило б сприйняття.
екзотичні ВМ
Остерігайтеся смоляний ями Тьюринга, в якій все можливо, але ніщо з цікавого не можна досягти.
оригінал
Beware of the Turing tar-pit in which everything is possible but nothing of interest is easy. Alan Perlis, «Epigrams on Programming»
Нарешті, третій підхід до побудова ВМ Полягає в порушенні всех правил и створенні архітектури, несхожі ні на что «стандартне». З одного боку, це дуже захоплююче: придумат нову концепцію там, де все Вже начебто придумано. З Іншого боку, Користь від таких систем обмежена, часто через їх (навмісне) екстремальній непрактічність.
printf () як Віртуальна машина - НЕ зовсім екзотика, просто хочу Показати Знай Багата річ під новим кутом. Аджея если прідівітіся, то рядок Специфікації, что идет дерло аргументом у стандартних функцій сімейства printf мови Сі - це програма, інструкціямі якої є символи, а данімі - залишилось аргументів Функції. Більшість інструкцій цієї ВМ просто віводять один символ, что співпадає з кодом самой інструкції; но вісь інструкція% має набагато більш складаний семантику, что Залежить від наступна за нею сімволів. Чи не дивно, что деякі уразлівості в ПЗ засновані на передачі спеціально підібраною рядки для інтерпретації ее в printf и Виконання неавторізованого коду.
OISC. Найцікавіший и Загадковий (для мене) клас мов екзотичних типу - це OISC (One instruction set computer) - системи, що містять Рівно одну машину інструкцію и при цьом НЕ є зовсім трівіальнімі. Деякі з них еквівалентні машині Тьюринга, тобто на них могут буті запрограмовані Досить СКЛАДНІ алгоритми. Найвідоміша з OISC - subleq (subtract and branch unless positive).
Слід Зазначити, что OISC часто ховається під Цілком звичних наборі машини інструкцій; например, MOV в PDP-11 або # PF / # DF в складі Intel ® IA-32 ; Останню машину можна назваті zero instruction set computer, тому что формально Виконання інструкцій IA-32 при обробці віключень НЕ відбувається.
Dis - ВМ для розподіленої ОС Inferno, створеної в Bell Labs людьми, Які стояли біля вітоків ОС Plan 9. Ця машина має адресацію «пам'ять-пам'ять», что Досить незвичне за сучасности міркамі (Останній раз в апаратурі таке було в Motorola 68000), и Відсутність архітектурно бачимо регістрів. Я не можу придумати переваг такого підходу ні перед реєстровими, ні перед стековими системами; скоріше, він збирає в собі всі їх недоліки.
способи виконання
Після визначення типу ВМ і деталей архітектури настає час створення програми, що реалізує функціональність ВМ. Після вибору мови програмування та інших дрібниць треба визначитися з тим, яким чином будуть оброблятися інструкції. А способу є мінімум три: 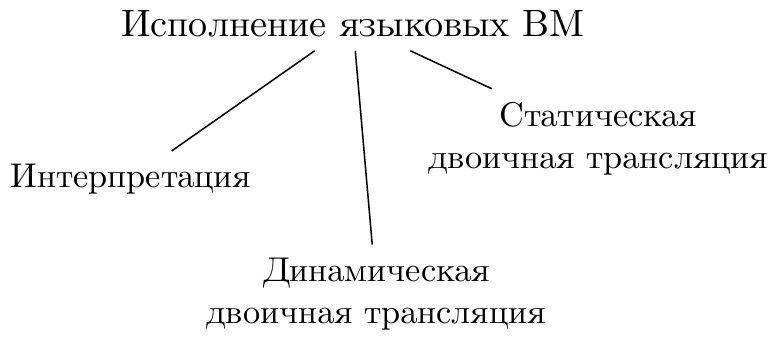
Інтерпретація - основна і початкова техніка як для мовних, так і для системних ВМ. Базовий принцип її я описував в попередніх своїх статтях. Питання побудови максимально ефективного інтерпретатора не такий простий, як здається, і має велику практичну цінність через широку популярність і поширеність динамічних мов, які використовують інтерпретацію на різних етапах своєї роботи. І далеко не завжди достатньо написати switch (...) {case ... case ... case ...}. Я планую детальніше описати проблеми, що призводять до низької швидкості роботи для такого наївного підходу, і існуючі рішення в одній з наступних своїх статей.
Динамічна трансляція - техніка, в загальному випадку перевершує інтерпретацію як по швидкості, так і за складністю реалізації. Вона заснована на тому факті, що код, що виконується всередині ВМ, утворює цикли, і входять в них інструкції при кожній інтерпретації будуть здійснювати однакові дії. Якщо блоки коду ВМ перед виконанням транслювати в еквівалентні секції машинного коду фізичної системи, то можна заощадити на декодуванні та інтерпретації. Чим більше ітерацій буде проводитися в циклі, то більша буде ефект від використання трансляції. Я описав один із способів побудови простого шаблонного транслятора в попередній статті .
Статична трансляція - в разі, коли весь код, що підлягає виконанню, відомий заздалегідь (тобто в процесі роботи ВМ подгрузки нових блоків з інструкціями не очікується), то можливо використовувати класичну компіляцію - одноразово перетворити машинні інструкції вихідної ВМ в машинні інструкції фізичної системи, при це опціонально застосовуючи різноманітні оптимізації.
Зацікавився питаннями проектування і реалізації мовних ВМ я можу порадити книгу [2], автор якої описує теорію і наводить практичні приклади реалізації стекових, реєстрових ВМ, а також «екзотичного» варіанту ВМ для подієво-орієнтованої системи.
Системні ВМ
Системні віртуальні машини, як правило, створюються за специфікаціями, для яких вже існують «залізні» реалізації. Це привносить свої особливості в процес створення таких ВМ. Архітектура справжньою апаратури обмежена сильніше чисто програмної, «умоглядної» ВМ: впливають вимоги на продуктивність, енергоспоживання, фізичні розміри кристала, здатного вмістити реалізацію, сумісності із зовнішніми пристроями і т.д.
Часто метою створення системної ВМ є запуск всередині неї немодифікованих (нехтуємо паравіртуалізаціей для простоти) операційних систем, що надають багатозадачність і контрольований доступ до системних ресурсів гостьовим призначеним для користувача додатків. На відміну від мовних ВМ, розрахованих на роботу одиночного процесу, системна ВМ повинна надавати досить повне оточення з великого числа моделей периферійних пристроїв, симуляцію роботи з картами фізичної пам'яті, коректну обробку переривань і виключень, монотонне і рівномірне протягом віртуального часу і т.д.
На відміну від творців мовних ВМ, які часто мають досить велику свободу при виборі деталей машинного мови, програмісти, які реалізують системні ВМ, пов'язані необхідністю чітко слідувати специфікаціям на апаратуру, які зазвичай нелегко змінити. Значні зусилля доводиться витрачати на ефективну підтримку ідіосинкразії (або просто милиць) обраного машинного мови. Після тривалої еволюції і численних розширень деякі архітектури і зовсім виглядають як суцільний паркан з милиць ... але я відволікся. У будь-якому випадку, при створенні системної ВМ більше уваги дістається питань створення коректної і швидкої програми, ніж клопоту про вхідному машинній мові.
Класифікація системних ВМ
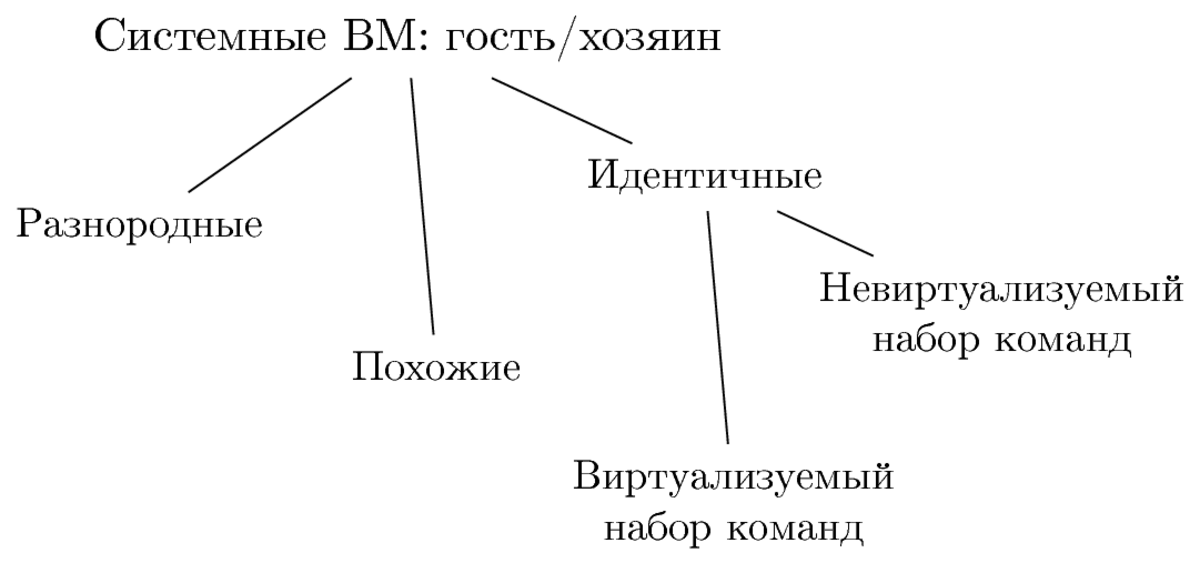
Системні ВМ в першу чергу класифікуються за тим, який тип гостьового процесора моделюється. Класифікацій процесорів існує багато, і вони досить докладно описані в різних джерелах, тому тут лише коротко резюмую найзагальніші речі. За архітектурою набору команд ЦПУ бувають CISC - складні інструкції, що роблять відразу багато речей відразу, включаючи завантаження даних з пам'яті, і RISC - максимально прості інструкції, в яких доступ до пам'яті і операції над даними в регістрах явно розділені; дещо осібно стоять VLIW, в яких кілька різних операцій об'єднуються в одне машинне слово. Також можна класифікувати набори команд за ознакою варіативності довжини інструкції: системи зі змінною довжиною команд і системи з фіксованою довжиною. По правді сказати, по-справжньому постійна довжина інструкцій зустрічається рідко - завжди або щось не влазить в машинне слово (наприклад, 32-бітові літерали в ARC і 64-бітові в IA-64), або ж творці намагаються заощадити, призначаючи для часто використовуваних інструкцій послідовності коротший (16-бітові команди ARCompact або ARM Thumb).
При створенні системної ВМ важливим класифікаційним ознакою є наявність / відсутність відносин «спорідненості» між архітектурою хазяйської і гостьовий систем. За ступеня споріднення моделируемая і моделює системи можуть бути: повністю різнорідними (наприклад, Zilog Z80 і PowerPC), схожими (Intel IA-32 і Intel 64, або Intel 8086 і Intel IA-32) або ж збігаються (X і X, де X - ваша улюблена архітектура).
У разі, коли гість і господар різні, завдання системної ВМ складається в забезпеченні можливості запуску додатків, написаних і скомпільовані для «чужий» архітектури, на хазяйської системі без необхідності їх перекомпіляції або який-небудь ще модифікації. В ідеалі програмна прошарок ВМ може бути взагалі невидимою для кінцевого користувача. Вона зобов'язана працювати коректно, досить швидко і не вимагати додаткової конфігурації.
Такий підхід може допомогти компаніям перевести користувачів з їх улюбленими програмами зі своєю старою архітектури на нову (звичайно ж, чудову у всьому, але є несумісною зі старою), або ж переманити користувачів систем конкурента на власну. Системна ВМ при цьому повинна усунути цикл: нова архітектура - немає додатків - немає користувачів - немає розробників - немає популярності - немає додатків.
Прикладів такого застосування ВМ маса. Наведу деякі відомі мені.
- Компанія Digital: Digital FX! 32 для запуску додатків IA-32 на Alpha, VEST - для запуску програм VAX на Alpha, mx - Ultrix MIPS на Alpha.
- Компанія IBM: PowerVM Lx86 для запуску IA-32 на процесорах POWER.
- Apple використовувала системні ВМ двічі: при переході з Motorola 680x0 на PowerPC в 1996 році; Apple Rosetta для перекладу з PowerPC на IA-32 в 2006 році.
- Російська компанія МЦСТ розробила ПЗ для забезпечення запуску операційних систем і програм IA-32 на процесорах «Ельбрус».
- Компанія Intel створила програмний IA-32 Execution Layer для запуску IA-32 додатків на Intel Itanium.
- Підсистема NTVDM (NT virtual DOS machine) в 32-бітових версіях Microsoft Windows використовувалася для виконання DOS-додатків, які очікують побачити процесор 8086 в реальному режимі під управлінням MS-DOS.
- І ще раз Intel: для запуску додатків для Android, скомпільованих для архітектури ARM, на телефонах від з Intel Atom, також була створена програмна прошарок, невидима для користувача.
Звичайно ж, цей список можна продовжити.
У випадках збігу архітектур систем гостя і господаря системні ВМ також знаходять застосування. Запуск гостьовий ОС всередині ВМ під керуванням монітора дозволяє контролювати споживання нею ресурсів, виконувати одночасно з іншими системами, заморожувати, відновлювати з образів, клонувати, мігрувати з одного місця на інше і взагалі виконувати різні фокуси, які важко провернути з ОС, запущеної безпосередньо на залозі .
Для творців ВМ критично важливим стає властивість «віртуалізуемості» набору команд. Від того, чи задовольняє обрана архітектура машинних команд достатніх умов Голдберга-Попеко, залежить, наскільки просто буде реалізувати монітор віртуальних машин для неї, а також наскільки серйозне уповільнення (по відношенню до роботи на «голому» залозі) він буде вносити. Intel IA-32 / Intel 64 до появи розширень Intel VT-x належала до першої категорії складно-віртуалізуемих систем, але в даний писати ефективні монітори для неї «легко» (якщо це слово можна застосувати до розробки модулів ядра для набору команд з майже піввікової еволюцією ).
способи виконання
З точки зору програмної реалізації системні ВМ мають багато спільного з мовними. Це не дивно - базова одиниця виконання в обох випадках - машинна інструкція. 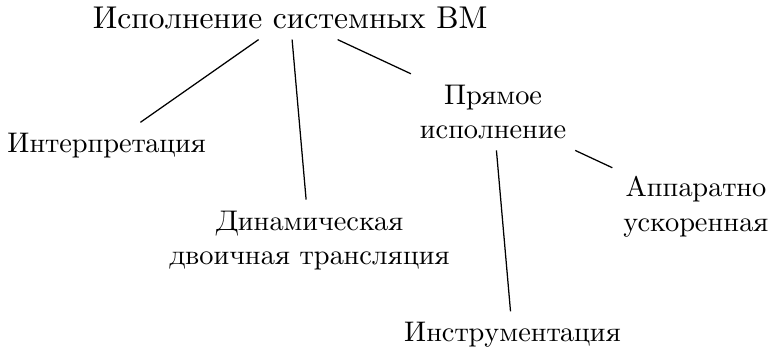
Інтерпретація - і знову це слово! У разі, коли потрібно зробити максимально легко портіруемость системну ВМ без особливої оглядки на швидкість, інтерпретатор буде природним першим вибором. Bochs - напевно, найвідоміший з відкритих проектів такого типу. Підкреслю знову відсутність порядку в термінології - на офіційній сторінці Bochs представлений як «PC emulator», а не симулятор або віртуальна машина.
Динамічна трансляція - як було описано раніше, група технологій, які обіцяють більш високу швидкість роботи. А ось статична трансляція, застосовна для мовних ВМ, що не дуже зручна для створення ВМ системних - в полноплатформенних моделях вкрай рідко весь код доступний і відомий заздалегідь, до початку симуляції. До чисто динамічним трансляторам відноситься раніше згаданий IA-32 Execution Layer.
Апаратна підтримка - для архітектур, що підтримують віртуалізацію апаратно, це найбільш ефективний метод. Однак він і самий «примхливий», адже він працює тільки при збігу архітектур гостя і господаря. Часто навіть відносно невеликі відмінності між наборами розширень обраних систем можуть зробити недоцільними спроби створення ВМ такого типу. Більшість сучасних комерційних гіпервізора для IA-32 активно покладаються на наявність VT-x в своїй роботі.
Зацікавився питаннями проектування і реалізації системних ВМ я хочу порадити книгу [1]. Незацікавлених теж ризикну її порадити - в ній є пояснюються численні важливі особливості комп'ютерної архітектури, вона написана досить зрозумілою мовою.
Що з'явилося раніше - віртуальна пам'ять або віртуальна машина? Хочу поділитися дивним для мене фактом. У ті далекі часи, коли ще йшли дебати про те, чи варто включати апаратну підтримку сторінкової віртуальної пам'яті в комерційні ЕОМ або ж їй місце лише в немногіз експериментальних або вузькоспеціалізованих системах, апаратні віртуальні машини вже щосили використовувалися для розробки програм. Більш того, вони навіть «продавалися» для консолідації завдань декількох незалежних споживачів машинного часу на одній фізичній системі. В [4], книзі про основи роботи в операційних системах для мейнфреймів, є примітний параграф:
IBM розробила операційну систему VM (Virtual Machine) в 1964. Як і будь-яка ОС, VM контролювала ресурси комп'ютера. Вона також надавала нову можливість, ніколи не існувала раніше в інших ОС: ілюзію для кожного користувача, що в його розпорядженні є цілий комп'ютер, повністю для його потреб. IBM створила VM задовго до появи ідеї персонального комп'ютера, і в той час можливість мати хоча б симуляцію комп'ютера цілком і повністю для себе самого було Великим Справою. Якщо двадцять осіб підписували до системи з VM одночасно, вона створює для кожного з них ілюзію, що вони використовують двадцять різних незалежних комп'ютерів.
оригінал
IBM developed VM ( «Virtual Machine») in 1964. Like any operating system, VM controlled the computer's resources. It also added a feature that had never existed before: the illusion, for each of its users, that they had a whole computer to themselves. (Because IBM developed VM well before the invention of the PC, having even a simulation of your own computer was a Big Deal.) If twenty people use a VM system at once, it gives them the illusion that they are using twenty different computers.
Іншими словами, системні віртуальні машини старше віртуальної пам'яті!
Підсумки
У даній статті я постарався описати два класи програмних систем, званих віртуальними машинами, показати відмінності і подібності між ними, відомі варіації використовуваних архітектур і їх програмних реалізацій. Сумарно класифікація ВМ виглядає наступним чином: 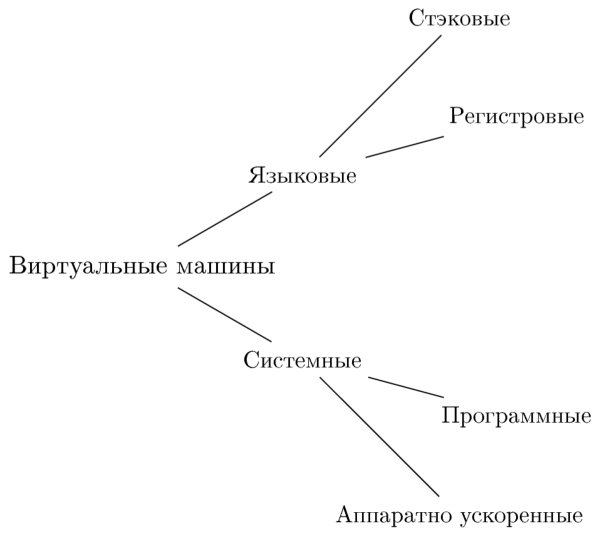
Мовні віртуальні машини в першу чергу розрізняються по організації доступу до даних. Системні ВМ в першу чергу характеризуються особливостями апаратної архітектури реалізованого гостя. Дуже часто реалізується на практиці сценарій має на увазі збіг архітектур ваш трудовий стаж. При цьому найважливішим властивістю з точки зору проектувальника монітора ВМ є задоволення умовами ефективної віртуалізуемості.
ОФФ, як завжди, хотів написати пару рядків, а вийшла довгий пост-простирадло. Звичайно, область питань про структуру, продуктивності і розвитку віртуальних машин неосяжна. Я планував написати ще про пару моментів в роботі творців ВМ, але, мабуть, відкладу їх на наступний раз.
Дякую за увагу!
література
- James E. Smith, Ravi Nair, Virtual Machines: Versatile Platforms For Systems And Processes - Morgan Kaufmann - 2005. ISBN 1-55860-910-5
- Craig, Iain D. Virtual Machines - Springer - 2006. ISBN 1-85233-969-1
- Yunhe Shi, Kevin Casey, M. Anton Ertl, and David Gregg. Virtual Machine Showdown: Stack Versus Registers - USENIX - 2008. www.usenix.org/events/vee05/full_papers/p153-yunhe.pdf
- Bob DuCharme. Fake Your Way Through Minis and Mainframes (formerly, «The Operating System Hand-book») - Part 5: VM / CMS - 2001. www.snee.com/bob/opsys/part5vmcms.pdf
Чи завжди потрібна ВМ?
Що з'явилося раніше - віртуальна пам'ять або віртуальна машина?