Закінчивши з реалізацією дерева як структури даних, розглянемо приклади його застосування при вирішенні деяких реальних завдань. Цей розділ буде присвячений деревам синтаксичного розбору. Вони можуть використовуватися для подання таких конструкцій реального світу, як пропозиції природної мови або математичні вирази. 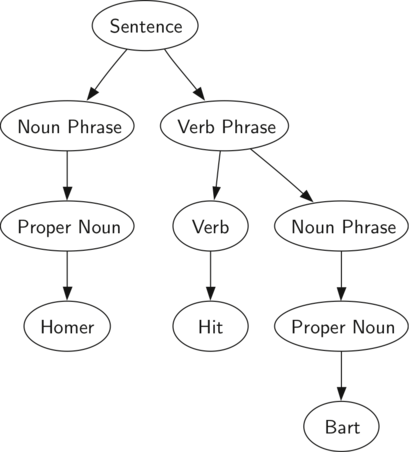
Малюнок 1: Дерево синтаксичного розбору простого пропозиції
на малюнку 1 зображена ієрархічна структура простого речення. Таке уявлення дозволяє нам працювати з його окремими частинами, використовуючи піддерева.
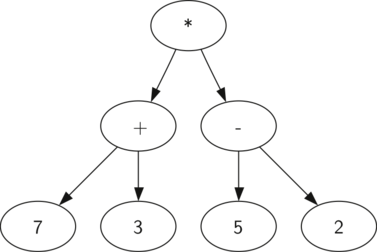
Малюнок 2: Дерево синтаксичного розбору виразу \ (((7 + 3) * (5-2)) \)
Також у вигляді дерева синтаксичного розбору можна уявити математичний вираз на кшталт \ (((7 + 3) * (5 - 2)) \) (див. малюнок 2 ). Ми вже розглядали вираження з повною розстановкою дужок: виходячи з цього, що можна сказати про даному прикладі? Нам відомо, що множення має вищий пріоритет, ніж додавання і віднімання. Однак, завдяки дужках ми знаємо, що тут спочатку потрібно обчислити суму і різницю. Ієрархія дерева допомагає краще зрозуміти порядок обчислення виразу в цілому. Перед тим, як знайти варте на самому верху твір, потрібно провести додавання і віднімання в піддерево. Перша операція - ліве піддерево - дасть 10, друга - праве піддерево - 3. Використовуючи властивість ієрархічної структури, ми можемо просто замінити кожне з піддерев на вузол, що містить знайдений відповідь. Ця процедура дасть спрощене дерево, показане на малюнку 3 .
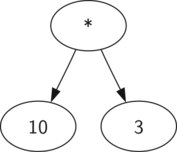
Малюнок 3: Спрощене дерево синтаксичного розбору для \ (((7 + 3) * (5-2)) \)
До кінця цього розділу ми збираємося як слід протестувати дерева синтаксичного розбору. Точніше, буде розглянуто:
- Як побудувати дерево розбору для математичного виразу з повною розстановкою дужок.
- Як обчислити вираз, що зберігається в дереві розбору.
- Як записати оригінальне математичне вираз з дерева розбору.
Перший крок при постороенние дерева синтаксичного розбору - це розбити рядок вираження на список токенов. Їх налічується чотири види: ліва дужка, права дужка, оператор і операнд. Ми знаємо, що прочитана ліва дужка завжди означає початок нового вираження і, отже, необхідно створити пов'язане з ним поддерево. І навпаки, зчитування правої дужки сигналізує про завершення вираження. Так само відомо, що операнди будуть листям і нащадками своїх операторів. Нарешті, ми знаємо, що кожен оператор має обох своїх нащадків.
Використовуючи сказану вище інформацію, визначимо такі правила:
- Якщо лічений токен '(' - додаємо новий вузол, як лівого нащадка поточного, і спускаємося до нього вниз.
- Якщо лічений один з елементів списку [ '+', '-', '/', '*'], то встановлюємо кореневе значення поточного вузла рівним оператору з цього токена. Додаємо новий вузол на місце правого нащадка поточного і спускаємося вниз по правому піддерев.
- Якщо лічений токен - число, то встановлюємо кореневе значення рівним цій величині і повертаємося до батькові чи матері.
- Якщо лічений токен ')', то переміщаємося до батькові чи матері поточного вузла.
Перед тим, як писати код на Python, давайте розглянемо в живу наведені вище правила. Ми будемо працювати з виразом \ ((3 + (4 * 5)) \) і розіб'ємо його наступним чином: [ '(', '3', '+', '(', '4', '*', ' 5 ',') ',') ']. Починати будемо з дерева розбору, що містить порожній кореневий вузол. малюнок 4 демонструє його структуру і вміст в міру обчислення кожного нового токена.
Малюнок 4: Трасування постороения дерева розбору.
Використовуючи цей малюнок, пройдемо за прикладом крок за кроком.
а) Створюємо порожній дерево.
б) Читаємо (в якості першого токена. За правилом 1 створюємо новий вузол, як лівого нащадка кореня. Робимо його поточним.
в) Прочитуємо наступний токен - 3. За правилом 3 встановлюємо значення поточного вузла в 3 і рухаємось назад до його батьків.
г) Наступним зчитуємо +. За правилом 2 встановлюємо кореневе значення поточного вузла в + і додаємо йому правого нащадка. Цей новий вузол стає поточним.
д) Прочитуємо (. За правилом 1 створюємо для поточного вузла лівого нащадка. Цей новий вузол стає поточним.
е) Прочитуємо 4. За правилом 3 встановлюємо значення поточного вузла рівним 4. Робимо поточним батька 4.
ж) Прочитуємо наступний токен - *. За правилом 2 встановлюємо кореневе значення поточного вузла рівним * і створюємо його правого нащадка. Він стає поточним.
з) Прочитуємо 5. За правилом 3 встановлюємо кореневе значення поточного вузла в 5, після чого поточним стає його батько.
і) Прочитуємо). За правилом 4 робимо поточним вузлом батька *.
к) Нарешті, зчитуємо останній токен -). За правилом 4 ми повинні зробити поточним батька +. Але такого вузла не існує, отже, ми закінчили.
З прикладу вище очевидна необхідність відслідковувати не тільки поточний вузол, а й його предка. Інтерфейс дерева надає нам способи отримати нащадків заданого вузла - за допомогою методів getLeftChild і getRightChild, - але як відстежити батька? Простим рішенням для цього стане використання стека в процесі проходу по дереву. Перед тим, як спуститися до нащадка вузла, проследній ми кладемо в стек. Коли ж треба буде повернути батька поточного вузла, ми виштовхни з стека потрібний елемент.
Використовуючи описані вище правила спільно з операціями з Stack і BinaryTree, ми готові написати на Python функцію для створення дерева синтаксичного розбору. Код її представлений в ActiveCode 1 .
Run Save Load Show in Codelens
Постороенние дерева синтаксичного розбору (parsebuild)
Чотири правила для постороения дерева розбору закодовані в перших чотирьох if ах 11, 15, 19 і 24 рядків ActiveCode 1 . У кожному разі ви бачите код, що втілює одне з описаних вище правил за допомогою декількох викликів методів класів BinaryTree або Stack. Єдина помилка, на яку в цій функції відбувається перевірка, - гілка else, що викликає виключення ValueError, якщо ми отримуємо токен, який не можемо рапознать.
Отже, дерево синтаксичного розбору побудовано, але що з ним тепер робити? Як перший приклад, напишемо функцію, яка обчислює дерево розбору і повертає числовий результат. Для цього будемо використовувати ієрархічну природу дерева. Подивіться ще раз на малюнок 2 . Нагадуємо: оригінальне дерево можна замінювати спрощеним, показаним на малюнку 3 . Це передбачає можливість написати алгоритм, який обчислює дерево розбору за допомогою рекурсивного обчислення кожного з його піддерев.
Як ми вже робили для рекурсивних алгоритмів в минулому, написання функції почнемо з виявлення базового випадку. Природним базовим випадком для рекурсивних алгоритмів, що працюють з деревами, є перевірка вузла на лист. У дереві розбору такими вузлами завжди будуть операнди. Оскільки об'єкти, подібні цілим або дійсним числам, не вимагають подальшої інтерпретації, функція evaluate може просто повертати значення, збережене в листі дерева. Рекурсивний крок, який просуває функцію до базового нагоди, буде викликати evaluate для правого і лівого нащадків поточного вузла. Так ми ефективно спустимося по дереву до його листя.
Щоб зібрати разом результати двох рекурсивних викликів, ми просто застосуємо до них збережений в батьківському вузлі оператор. У прикладі на малюнку 3 ми бачимо, що два нащадка кореневого вузла обчислюються в 10 і 3. Застосування до них оператора множення дасть остаточний результат, рівний 30.
Код рекурсивної функції evaluate показаний в лістингу 1 . Спочатку ми отримуємо посилання на правого і лівого нащадків поточного вузла. Якщо обидва вони обчислюються в None, значить цей вузол - лист. Це перевіряється в рядку 7. Якщо ж вузол не листової, то шукаємо в ньому оператор і застосовуємо його до результатів рекурсивних обчислень лівого і правого нащадків.
Для реалізації арифметики ми використовуємо словник з ключами '+', '-', '*' і '/'. Збережені в ньому значення - функції з модуля операторів Python. Цей модуль надає в наше розпорядження безліч часто вживаних операторів у вигляді функцій. Коли ми шукаємо в словнику оператор, витягується пов'язаний з ним об'єкт. А оскільки це функція, то ми можемо викликати її звичайним способом function (param1, param2). Таким чином, пошук opers [ '+'] (2,2) еквівалентний operator.add (2,2).
лістинг 1
def evaluate (parseTree): opers = { '+': operator. add, '-': operator. sub, '*': operator. mul, '/': operator. truediv} leftC = parseTree. getLeftChild () rightC = parseTree. getRightChild () if leftC and rightC: fn = opers [parseTree. getRootVal ()] return fn (evaluate (leftC), evaluate (rightC)) else: return parseTree. getRootVal ()
Нарешті, простежимо роботу функції evaluate на дереві синтаксичного розбору, яка зображена на малюнку 4 . У першому виклику evaluate ми передаємо їй корінь всього дерева в якості параметра parseTree. Потім отримуємо посилання на лівого і правого нащадків, щоб переконатися в їх існуванні. У рядку 9 йде наступний рекурсивний виклик. Ми починаємо з пошуку оператора в корені дерева, яким в даному випадку є +. Він відображається як виклик функції operator.add, що приймає два параметри. Традиційно для виклику функції першим, що зробить Python, стане обчислення переданих у функцію параметрів. У нашому випадку обидва вони - рекурсивні виклики evaluate. Обчислюючи зліва направо, спочатку виконається лівий рекурсивний виклик, куди передано ліве піддерево. Ми виявимо, що цей вузол не має нащадків, отже, є листом. Тому що зберігається в ньому значення просто повернеться, як результат обчислення. В даному випадку це буде ціле число 3.
До теперішнього моменту у нас є один параметр, обчислений для верхнього виклику operator.add. Але ми ще не закінчили. Продовжуючи обчислювати параметри зліва направо, зробимо рекурсивний виклик для правого піддерева кореня. Виявивши, що у нього є і правий, і лівий нащадки, шукаємо оператор, що зберігається в вузлі, ( '*') і викликаємо для нього функцію, передаючи в неї лівого і правого нащадків в якості параметрів. У цій точці обчислення обидва рекурсивних виклику повернуть листя - цілі 4 і 5, відповідно. Маючи їх, повернемо результат operator.mul (4,5). Тепер у нас є всі операнди для верхнього оператора +, і залишається просто викликати operator.add (3,20). Результат обчислення дерева для вираження \ ((3 + (4 * 5)) \) дорівнює 23.
Ми вже розглядали вираження з повною розстановкою дужок: виходячи з цього, що можна сказати про даному прикладі?Інтерфейс дерева надає нам способи отримати нащадків заданого вузла - за допомогою методів getLeftChild і getRightChild, - але як відстежити батька?
Отже, дерево синтаксичного розбору побудовано, але що з ним тепер робити?