- Data Science Virtual Machine
- Виртуалки з GPU
- Процес створення VM
- Процес настройки VM
- Простий запуск і зупинка VM
- Зберігання даних
- Best Practice
- висновок
- Posted in Майкрософт and технології by Митя Сошників on травня 31st 2017 at 00:08.
Для задач машинного навчання як правило потрібні чималі ресурси: як обчислювальні, так і для зберігання даних. Тому все більша кількість фахівців з аналізу даних (датасайнтістов) звертають свій погляд у бік хмарних ресурсів.
Для всіх, хто хоче використовувати хмара для машинного навчання або глибокого навчання нейромереж, у нас є хороша новина - хмара Microsoft Azure прекрасно вам підійде! І ось чому:
- У Azure є готовий образ Data Science Virtual Machine, як під управлінням Windows, так і під Linux, на яких вже встановлено все необхідне вам програмне забезпечення!
- У нашому хмарі вам доступні комп'ютери з графічними процесорами NVidia (т.зв. N-Series VMs), що сильно прискорює процес навчання нейромереж.
У цьому пості я розгляну інструкцію по створенню та налагодженню віртуальної машини для глибокого навчання в хмарі. При цьому я буду припускати, що у вас вже є хмарна підписка Microsoft Azure, прив'язана в вашому Microsoft Account - якщо це не так, то можна обзавестися пробної підпискою .
Data Science Virtual Machine
Для задач обробки даних добре підходить спеціалізована віртуальна машина Data Science Virtual Machine. На ній спочатку вже встановлені:
- Visual Studio і Visual Studio Code, з підтримкою R і Python
- Anaconda - найпопулярніша cреда для підтримки різних оточень на Python і не тільки
- Всі необхідні фреймворки для навчання нейромереж: Microsoft Cognitive Toolkit (CNTK), Tensorflow, MXNet і ін. Причому якщо ви використовуєте виртуалку з GPU - все утиліти і бібліотеки для роботи з GPU (драйвера NVidia, CUDA, cuDNN і ін.) Будуть вже налаштовані .
- Jupyter Notebooks
- Microsoft R
- Всі необхідні бібліотеки і утиліти для доступу до Azure
- Багато корисних утиліт (github, AzCopy, ...) і іншої смакоти
Віртуальні машини доступні як для Windows, так і для Linux:
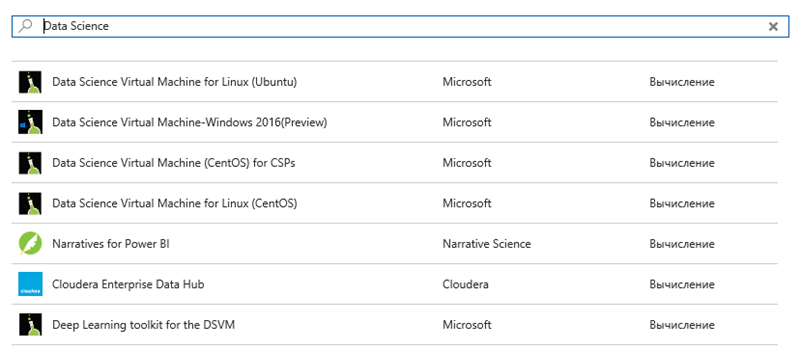
При цьому є тонкощі:
- Data Science Virtual Machine for Windows 2016 - це найкращий варіант! Може ставиться як на GPU (причому як NC, так і NV - докладніше про це нижче), так і на звичайну VM.
- Deep Learning Toolkit for DSVM - це старіша версія віртуальної машини для глибокого навчання на базі Windows Server, яка ставиться тільки на виртуалки типу NC (яких іноді може не вистачати).
- З Linux-варіантів підтримка GPU є тільки в Ubuntu, але зате і вибір фреймворків там трохи ширше.
Виртуалки з GPU
У Azure є 2 типу віртуалок з GPU (т.зв. N-Series VMs):
- NC (Compute) - призначені для обчислень і глибокого навчання. Оскільки такі виртуалки користуються значною популярністю, їх може іноді не вистачати в тих чи інших регіонах.
- NV (Visualisation) - призначені для запуску додатків графічної візуалізації. Проте, на цих віртуалкою теоретично можна вважати нейромережі, хоча робити це не рекомендується. І стоять вони трохи дорожче.
Віртуальні машини з GPU доступні лише в деяких регіонах, тому якщо вам не пропонують NC або NV в якості опції при виборі типу виртуалки - спробуйте вибрати інший регіон. Починати варто з США (South-Central US, East US) або Європи (North Europe). Ось на цій сторінці можна подивитися доступність в різних регіонах, вибираючи їх з drop-down вгорі сторінки.
Процес створення VM
Нижче описується процес створення та налаштування Data Science VM на GPU.
1. Заходимо на Azure Portal і вибираємо вгорі пункт "створити":
2. У рядку пошуку пишемо Data Science і отримуємо на вибір кілька варіантів, наведених на малюнку вище.
3. Вибираємо потрібні варіант і натискаємо "Створити". Після цього переходимо ось до такого екрану конфігурації:
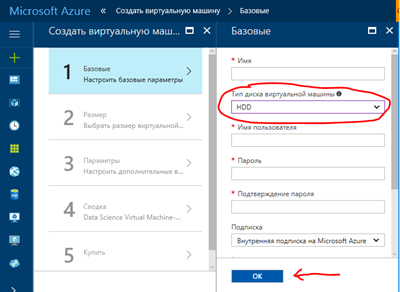
4. При установці машини з GPU як диска обов'язково вибрати HDD, оскільки N-Series VM не бувають з SSD, і якщо вибрати SSD-потім не буде доступна опція вибору N-Series.
5. Вибираємо ім'я користувача, пароль і т.д. Також вибираємо ім'я нової ресурсної групи, куди будуть поміщені всі хмарні об'єкти, прив'язані в цій віртуальній машині - сховище для дисків, сама виртуалка, мережеві інтерфейси і т.д.
6. Як регіону вибираємо відповідний регіон за принципом, описаним вище. Якщо в обраному регіоні не виявиться доступних VM з GPU - потім можна буде повернутися і змінити його.
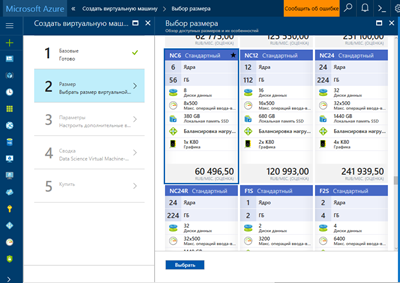
7. Наступним пунктом вибираємо розмір і тип виртуалки. NC6 - це найпростіша виртуалка з графічним процесором, і як бачимо на поточний момент вона коштує близько 60000 руб. у місяць.
8. У розділі "додаткові параметри" в принципі можна нічого не налаштовувати, якщо ви просто створюєте одну вірталку. Якщо ж у вас вже є якась віртуальна підмережа, або ви налаштовували раніше мережевий доступ для іншої VM - тут є певний простір для оптимізації.
9. На останньому екрані читаємо ще раз вибрану конфігурацію і натискаємо "Купити".
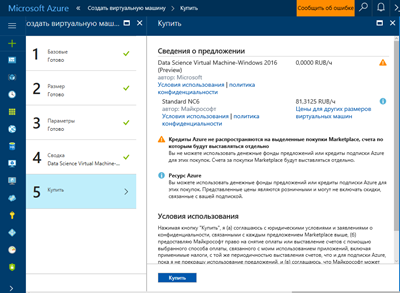
10. Після цього машина довго і болісно (більше 10 хвилин) створюється.
Процес настройки VM
На цьому етапі ви вже можете зайти в свою виртуалку, натиснувши кнопку "Connect" на сторінці налаштувань (виділено червоним):
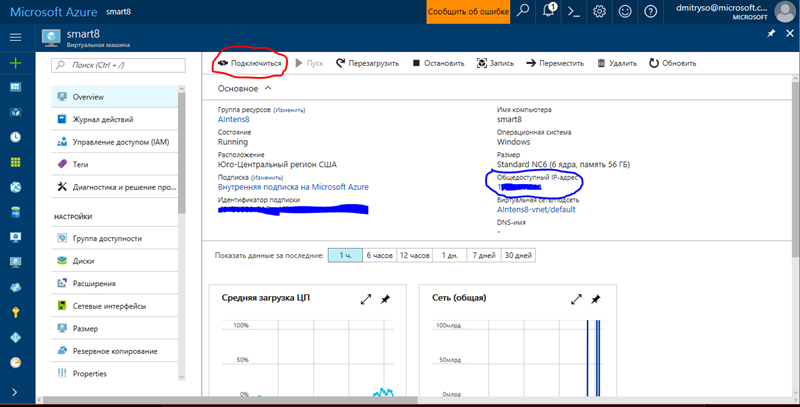
Однак для комфортної роботи з віртуальною машиною потрібно зробити ще кілька налаштувань:
1. Присвоїти машині зручне DNS-ім'я, щоб звертатися до неї по імені. Для цього треба натиснути на IP-адресу на сторінці вище (виділено синім), на сторінці ввести DNS-ім'я і натиснути "Зберегти":
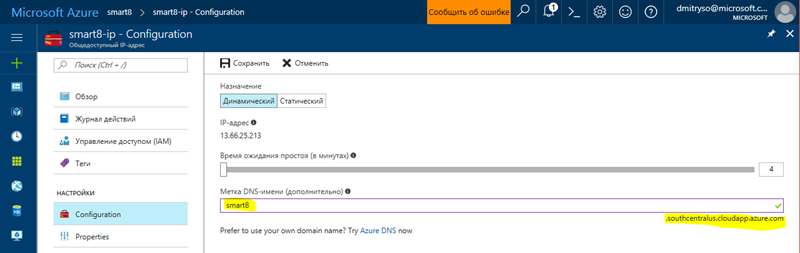
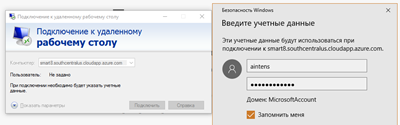
Також запам'ятайте закінчення адреси, що залежить від регіону. Для даної машини повний DNS-адреса буде smart8.southcentralus.cloudapp.azure.com. Тепер ви зможете просто підключатися до машини за допомогою віддаленого робочого столу, використовуючи DNS-адресу та ввівши зазначені раніше дані про користувача і пароль:
2. Дуже зручно проводити навчання нейромереж НЕ через віддалений термінал, а через браузер, використовуючи Jupyter Notebook. Для цього рекомендується налаштувати автоматичний запуск Jupyter на виртуалке, а також пароль для доступу. Для цього увійдіть на машину через віддалений робочий стіл і запустіть ярлик, показаний нижче:
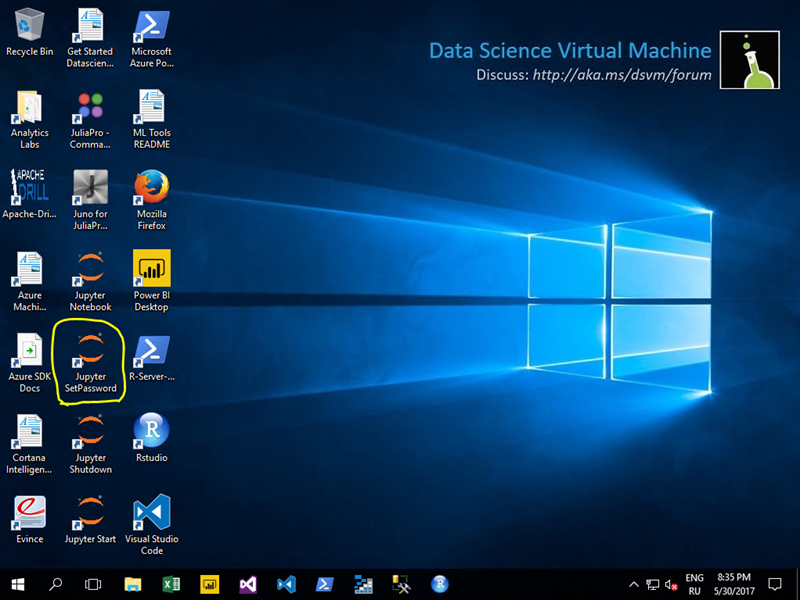
Після цього в який з'явився текстовому вікні необхідно двічі ввести пароль і натиснути ENTER.
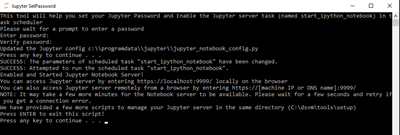
Після цього необхідно трохи почекати, і можна спробувати увійти в Jupyter з локального браузера за адресою https: // localhost: 9999 . При цьому ігноруйте повідомлення про те, що https-сертифікат невірний - сміливо переходите на сторінку, вводите встановлений раніше пароль і починайте працювати!
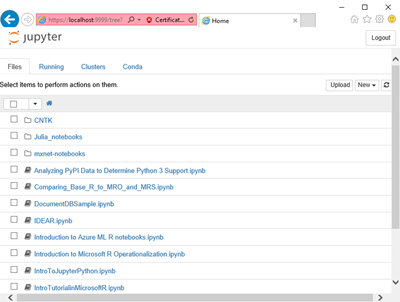
3. Для того, щоб Jupyter Notebook був доступний ззовні по порту 9999, необхідно додати запис в Network Security Group для нашої машини (якщо це не було зроблено за замовчуванням). В панелі управління Azure переходимо до групи ресурсів нашої виртуалки і вибираємо щось, що закінчується на -nsg:
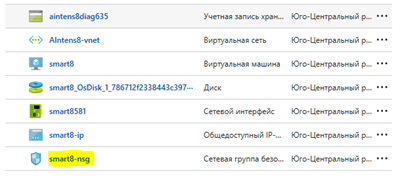
У вікні, ми повинні побачити приблизно такі правила:
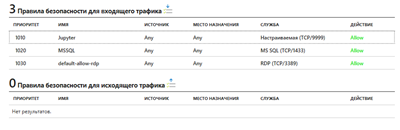
Якщо правила Jupyter з портом 9999 немає, то його необхідно додати вручну, вказавши протокол TCP і порт 9999.
Після цього ви повинні бути в змозі зайти на Jupyter Notebook вашої машини, просто вказавши в браузері адресу https://smart8.southcentralus.cloudapp.azure.com:9999 і ввівши пароль, встановлений на попередньому кроці.
Простий запуск і зупинка VM
Оскільки машини з GPU дорогі, то рекомендується зупиняти виртуалки, коли ви їх не використовуєте. Так ви зможете знизити витрати з $ 1000 в місяць, до $ 70-150 (такий на даний момент мій типовий рахунок за хмару, якщо я не роблю чогось екстраординарного). Щоб кожен раз не заходити на Azure Portal, дуже зручно налаштувати спеціального Azure Bot в скайпі, який дозволить вам запускати і зупиняти машини простими командами.
Процес настройки бота такий:
1. Заходьте на http://botframework.com в розділ Bot Directory.
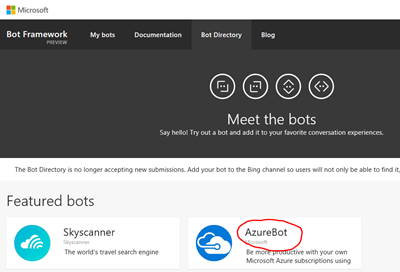
2. Як правило, Azure Bot буде доступний на першій сторінці. Якщо немає - знайдіть його!
3. Натискаєте на бота і встановлюєте його собі в Skype.
4. При першому діалозі з ботом треба буде аутентифицироваться - перейти за посиланням, залогінитися в Azure і скопіювати код з сайту в чат з ботом. Після цього бот вас запам'ятає, і робити це буде не потрібно.
5. Для зупинки і запуску віртуальних машин використовуйте команди start vm <ім'я>, stop vm <ім'я>
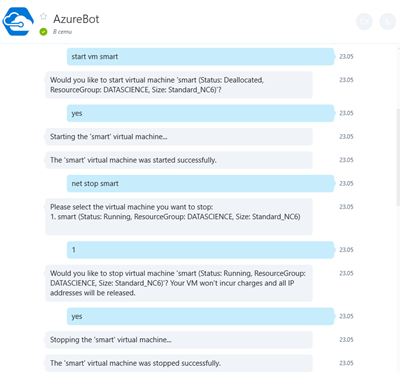
Зверніть увагу, що тільки таке виключення машини (DEALLOCATION) веде до того, що з вас перестають списувати гроші за її використання. Якщо ви просто в віддаленому терміналі скажете Shutdown - машина буде зупинена, але не деаллоцірована, і гроші продовжать списуватися. При деаллокаціі машини звільняються зайві ресурси, включаючи IP-адреси і тимчасові диски.
Зберігання даних
На закінчення хотілося б сказати кілька слів про зберігання даних. Разом з створеної машиною автоматично було створено два диска:
- Диск C: - системний. На ньому зберігаються всі програми і системні файли, і навіть є трохи місця. Вміст цього диска зберігається при деаллокаціі машини. Однак захаращувати його вашими даними - не дуже хороша ідея.
- Диск D: - це швидкий диск для тимчасових даних, його вміст між запусками машини буде губитися.
Для довгострокового зберігання даних, а також для поділу їх між машинами, можна використовувати такі підходи:
- Створити файлове сховище всередині Azure Storage і потім підключити його до своєї машини командою net use. Такий підхід має той плюс, що ви зможете також підключити той же сховище до своєї основної машині, і тим самим отримаєте простий спосіб обмінюватися даними. Однак файлове сховище щодо повільне, а якщо воно раптом розташоване в іншому регіоні - то зовсім повільне. Крім того, за пересилку даних між регіонами стягується якась плата.
- Створити віртуальний диск (Managed Disk) і підключити його до віртуальної машини. Віртуальні диски швидше, ніж файлові сховища, але їх складніше підключити до зовнішніх комп'ютерів.
Best Practice
Останнім часом я роблю кілька проектів з аналізу даних і навчання нейромереж, тому хочу поділитися з вами корисним прийомом використання віртуальних машин з GPU. Як відомо, 80% часу зазвичай витрачається на підготовку даних, і лише 20% - на власне запуск алгоритмів навчання. Тому я зазвичай маю у своєму арсеналі дві віртуальні машини, підключені до загального файлового сховища:
- Віртуальна машина для підготовки даних - це звичайна виртуалка, без GPU, досить потужна, щоб з нею було комфортно працювати з віддаленого доступу. Зазвичай я використовую щось типу DS2.
- Віртуальна машина для навчання - це NC6.
У кожен момент часу я запускаю ту машину, з якої планую працювати. При цьому в обох випадках всі дані і скрипти розташовуються на файловому сховищі, тобто я маю до них доступ звідусіль.
Однак для прискорення навчання я іноді копіюю дані з зовнішнього сховища на локальний диск (C: або D :, в залежності від того, наскільки довгострокові повинні бути ці дані).
висновок
Data Science Virtual Machine - це дуже простий і швидкий спосіб почати використовувати інструменти аналізу даних і глибокого навчання. Я сподіваюся, що мій досвід допоможе вам використовувати ці віртуальні машини в своїй роботі або дослідженнях. Якщо у вас є свій досвід використання віртуальних машин з GPU для аналізу даних - діліться досвідом в коментарях!
Мітки: Azure , CNTK , Data Science , Deep Learning , GPU , Neural Networks